有时我们需要匹配 ASCII 范围之外的字符,例如:中文、韩文、泰文等。在正则表达式中,可以使用 \u 语法通过 Unicode 来表示非 ASCII 范围内的字符。
什么是 ASCII?
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准 ISO/IEC 646。ASCII第一次以规范标准的类型发表是在 1967 年,最后一次更新则是在 1986 年,到目前为止共定义了128个字符(2的7次方,一个字节仅仅用了7个bit)。
什么是 Unicode?
Unicode(又称统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 码扩展自 ASCII 码。在严格的 ASCII 码中,每个字符用7位表示,电脑上普遍使用的每字符有8位宽;而 Unicode 使用全16位表示。这使得 Unicode 能够表示世界上所有的书写语言中可能用于电脑通讯的字符、象形文字和其他符号。
正则表达式广告位
匹配 Unicode 字符
前面介绍了 ASCII 和 Unicode 编码,在正则表达式中使用 \u 语法去匹配 Unicode 编码。比如:
\u5c71\u897f
上面两个 Unicode 编码将匹配 “山西” 字符串。如下图:
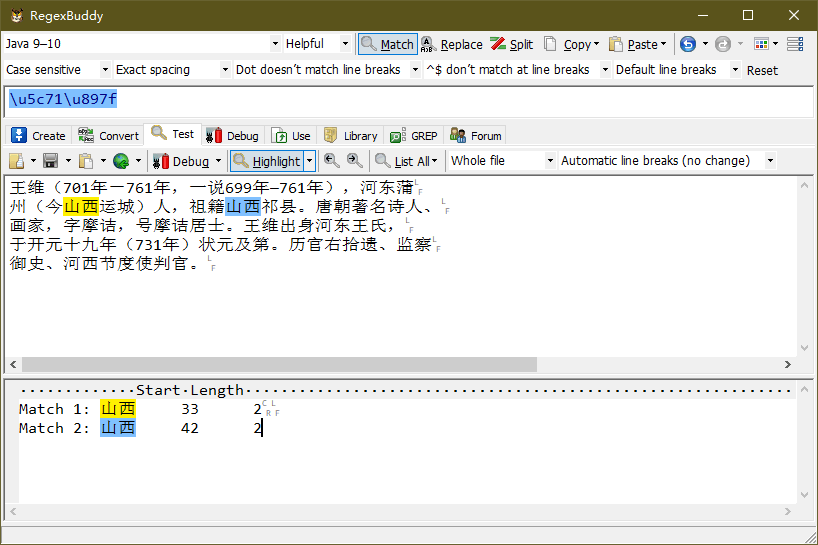
\u 之后紧跟十六进制 5c71 和 897f(注意:这里不区分大小写,即 5C71 和 897F 也可以)。5c71 和 897f 十六进制转换成十进制后,均在 ASCII 范围(0~127)之外。注意:\u 不能使用大写的 \U
匹配 Unicode 范围字符
上面介绍了怎样匹配单个 Unicode 字符。其实,正则表达式还支持匹配 Unicode 范围。例如:匹配所有中文字符,如下:
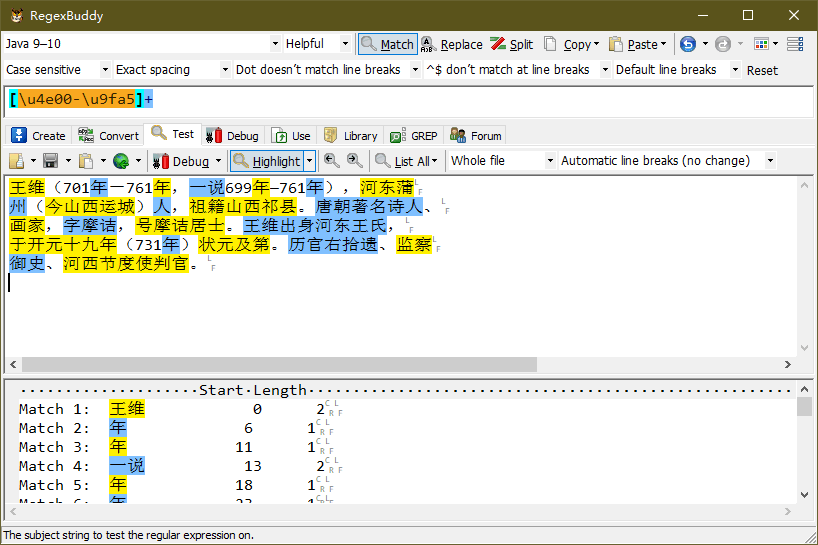
上图中,[\u4e00-\u9fa5] 将匹配所有的中文汉字,汉字对应的 Unicode 你可以自行网上查询。
匹配控制字符
正则表达式如何匹配控制字符呢?虽然你很少会在文本中查找控制字符,但知道怎样匹配控制字符不是一件坏事。
在正则表达式中,可以像这样来指定一个控制字符:
\cx
其中 x 就是你想要匹配的控制字符。

 川公网安备51010802032098
川公网安备51010802032098