前面章节介绍了捕获分组和分组引用,本章节将介绍非捕获分组。
在某些正则表达式实现中,也提供对非捕获分组的支持(注:非捕获分组是相对捕获分组而言),非捕获分组也称为 “仅分组的圆括号” 或 “非捕获圆括号”。
捕获分组会将匹配的内容临时存储于内存中,供后续引用。然而,非捕获分组(Non-Capturing Group)不会将其内容存储在内存中。如果你并不想引用分组的时候,可以使用非捕获分组。由于非捕获分组不会将匹配的内容存储到内存中,非捕获分组就会带来较高的性能。
假设要捕获两个字符序列,第一个序列是表示 Doctor 的不同形式,第二个序列是这个 Doctor 的姓。假如数据结构如下:
Doctor Firstname LastName
Dr Firstname LastName
Dr. Firstname LastName
可以通过下面的模式来捕获 Doctor 或者它的缩写形式,将 Doctor 不同形式匹配保存到 $1 变量中,把姓名保存在 $2 中,如下:
(Doctor|Dr\.|Dr)(\s\w{1,}\s)(\w{1,})
上面模式将创建三个分组,分别如下:
$1(分组1)—— 模式 “(Doctor|Dr\.|Dr)” 创建分组 $1 并捕获到 Doctor 或它的一种缩写形式
$2(分组2)—— 模式 “(\s\w{1,}\s)” 创建分组 $2 并捕获到一个空格字符、Dockor名字和另一个空格符
$3(分组3)—— 模式 “(\w{1,})” 创建分组 $3 并捕到了 Docker 的姓
正则表达式广告位
我们的本意仅仅是获取 $1 分组1,和 $2 分组2。然而,上面模式却创建了三个分组。此时,我们可以使用非捕获分组将第三个分组去掉,创建非捕获分组语法如下:
(?:the-non-captured-content)
换句话说,当在圆开括号后面放置一个问号和一个冒号时,相应的这对圆括号就不会再捕获内容了。如果把前面例子中的模式修改为:
(Doctor|Dr\.|Dr)(\s\w{1,}\s)(?:\w{1,})
运行如下图:
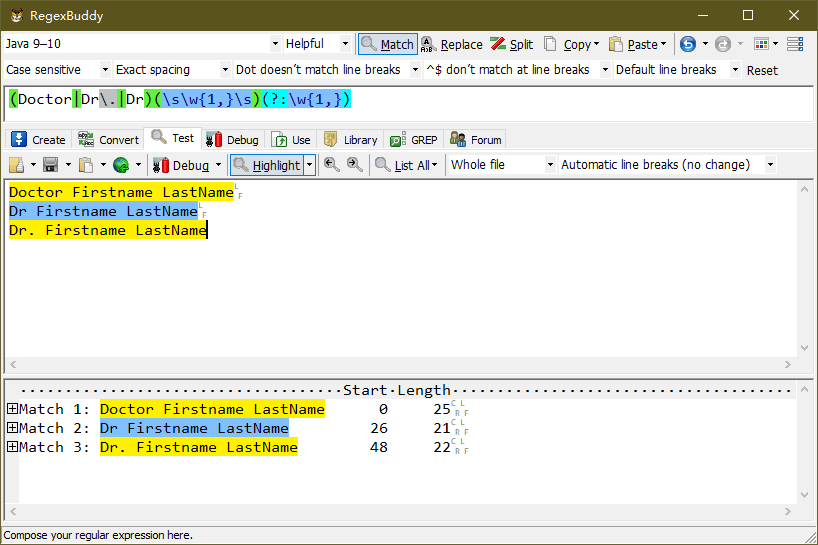
上图中,模式 “(Doctor|Dr\.|Dr)” 保存到 $1 分组中,而模式 “(\s\w{1,}\s)” 保存到 $2 分组中;然而,模式 “(?:\w{1,})” 不会捕获,也不会创建分组;
使用非捕获分组确实让这个模式看起来有点复杂;但是,在复杂的同时,他却能减少要处理的分组数,也能提高效率。

 川公网安备51010802032098
川公网安备51010802032098