本章节将介绍怎样使用正则表达式匹配一行的开始和结束位置。在正则表达式中,使用 ^ 元字符匹配开始位置,$ 元字符匹配结束位置。
行的起始 ^
根据上下文,^ 元字符会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。而上下文则依赖于应用程序和在应用程序中所使用的选项。
实例:使用“^[Bb]e” 匹配文档中所有行开头的 “Be” 字符,如下图:
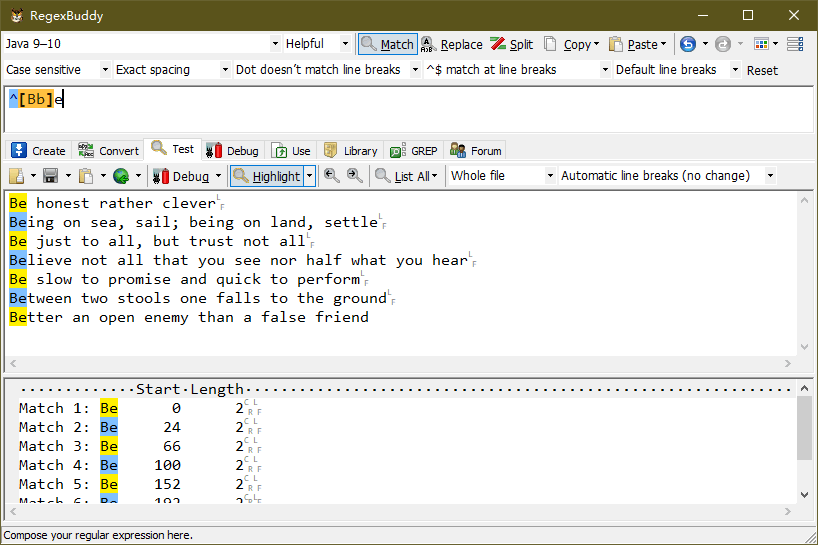
上图中,仅仅匹配了每行开始的 “Be” 字符串,并没有匹配第 2 行中的 “being” 字符串中的 “be” 字符串。
正则表达式广告位
行的结束 $
在正则表达式中,美元符 $ 用来匹配一行或者字符串的结束位置。
实例:使用 “nd$” 匹配文档中所有行尾的 “nd” 字符串。如下:
(1)如果我们将 “nd$” 模式后面的 “$” 符号去掉,匹配模式如下:
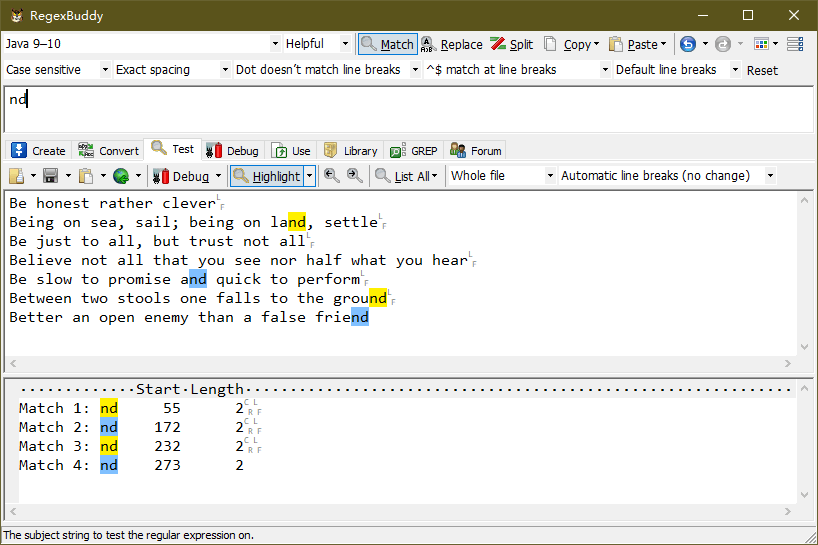
上图中,共匹配了4个 “nd” 字符串。
(2)使用添加了 “$” 元字符的表达式,匹配如下:
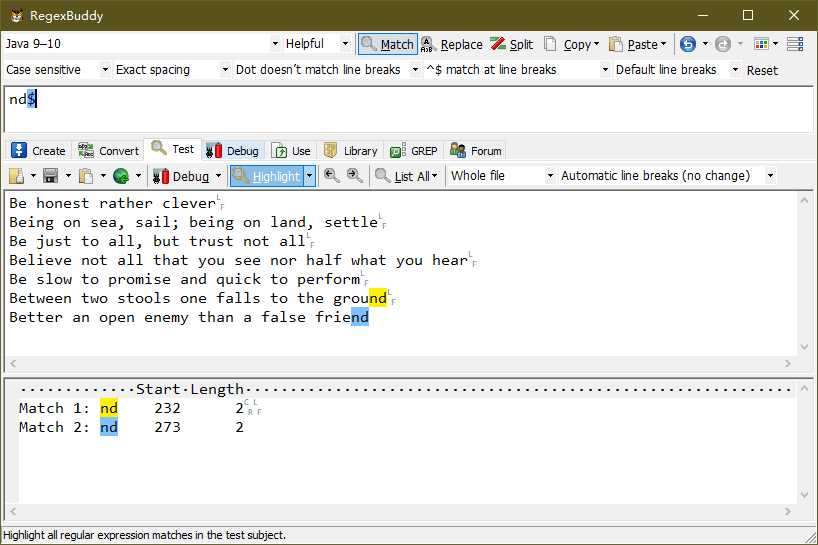
上图中,仅仅匹配了第6、7 行末尾的 “nd” 字符串,因为 $ 符号匹配行的末尾位置。
最后,我们可以配合 ^ 和 $ 两个元字符,匹配指定行首和行尾字符的一行文字。如下:
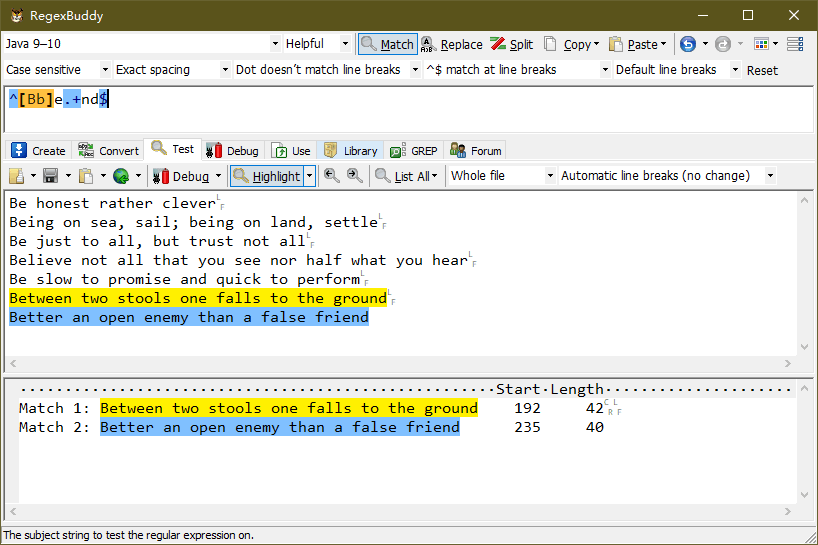
上图中,使用 “^[Bb]e.+nd$” 模式去匹配以 “Be” 或 “be” 开头,以 “nd” 结尾的一行字符串。

 川公网安备51010802032098
川公网安备51010802032098