Prometheus 自身包括一个本地磁盘时间序列数据库,因此支持本地数据存储,同时还支持远程存储。本章节将介绍 Prometheus 的本地存储。
本地存储
Prometheus 默认使用本地存储来存放数据,将数据保存在本地的磁盘上。这种存储方式适用于短期的数据存储,但随着数据量的增加,可能会遇到磁盘空间不足的问题。为了解决这个问题,Prometheus 提供了追加写(Append Write)功能,可以将旧的数据从本地存储中删除。
注意:Prometheus 的本地时间序列数据库以定制的高效格式在本地磁盘中存储数据。
磁盘布局
在了解磁盘布局前,我们先看看 Prometheus 本地存储数据的目录结构,如下图:
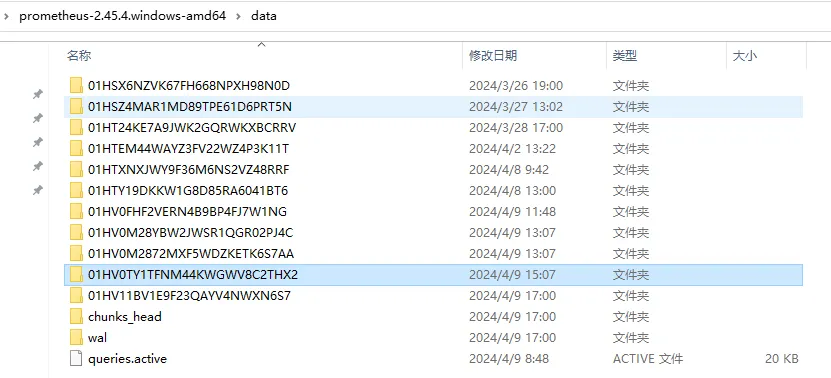

Prometheus 摄取的样本以两小时为一个组块(即在 data 目录一个子目录)。每两小时的数据块由一个目录(包含该时间窗口内所有时间序列样本的 chunks 子目录)、一个元数据文件(meta.json)和一个索引文件(index,用于索引 chunks 目录中时间序列的指标名称和标签)组成。默认情况下,chunks 目录中的样本会被分组到一个或多个段文件中,每个段文件的大小不超过 512MB。通过应用程序接口删除序列时,删除记录会存储在单独的 tombstones 文件中(而不是立即从块段中删除数据)。
prometheus 广告位
注意,Prometheus 输入样本的当前数据块将保存在内存中,不会完全持久化。它通过一个前置写入日志(WAL)来防止崩溃,当 Prometheus 服务器重新启动时可以重加载该日志。前置写日志文件以 128MB 的分段形式存储在 wal 目录中。这些文件包含尚未压缩的原始数据,因此比普通块文件大得多(因为没有被压缩)。Prometheus 将至少保留三个前置写日志文件,高流量服务器可能会保留三个以上的 WAL 文件,以便保留至少两小时的原始数据。如下图:

Prometheus 服务器的完整数据目录如下所示:
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── chunks_head
│ └── 000001
└── wal
├── 000000002
└── checkpoint.00000001
└── 00000000
需要注意的是,本地存储的局限性在于它没有集群或复制功能。因此,面对硬盘故障或单节点故障,本地存储将无能为力。建议使用 RAID(磁盘阵列)来提高存储的可用性,并建议使用快照来进行备份。通过适当的架构,可以在本地存储中保留多年的数据。
此外,还可通过远程读/写 API 接口使用外部存储。由于这些系统在可靠性、性能和效率方面差异很大,因此需要对它们进行仔细评估。
数据压缩
Prometheus 输入样本的当前数据块将保存在内存中,不会完全持久化。但是,这两小时数据块最终会在后台压缩成保存更长时间的数据块。
注意,压缩将创建更大的数据块,其中包含的数据最长可达保留时间的 10%,或 31 天,以较短者为准。
配置参数
Prometheus 有几个配置本地存储的标志。其中最重要的有:
--storage.tsdb.path:Prometheus 写入数据库的位置。默认为 data/。
--storage.tsdb.retention.time:何时删除旧数据,默认为 15 天。如果此标志设置为默认值以外的其他值,则覆盖 storage.tsdb.retention 参数。
--storage.tsdb.retention.size:要保留的存储块的最大字节数,最旧的数据将首先被移除。默认为 0 或禁用,支持的单位 B、KB、MB、GB、TB、PB、EB,例如:512MB。基于 2 次幂,因此 1KB 为 1024B。虽然 WAL 和 m-mapped 块会被计入总大小,但只有持久块才会被删除,以遵守这一保留规定。因此,对磁盘的最低要求是 WAL(WAL 和检查点)和 chunks_head(m-mapped Head 块)目录所占空间的峰值总和(每 2 小时达到峰值)。
--storage.tsdb.retention:已弃用,改用 storage.tsdb.retention.time。
--storage.tsdb.wal-compression: Enables compression of the write-ahead log (WAL). Depending on your data, you can expect the WAL size to be halved with little extra cpu load. This flag was introduced in 2.11.0 and enabled by default in 2.20.0. Note that once enabled, downgrading Prometheus to a version below 2.11.0 will require deleting the WAL.
--storage.tsdb.wal-compression: 启用前置日志(WAL)压缩。根据你的数据,你可以期待 WAL 的大小减半,而只需很少的额外 CPU 负载。此标记在 2.11.0 中引入,并在 2.20.0 中默认启用。请注意,一旦启用,将 Prometheus 降级到低于 2.11.0 的版本将需要删除 WAL。
Prometheus 平均每个样本只存储 1-2 个字节。因此,要规划 Prometheus 服务器的容量,可以使用以下公式粗略计算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
其中:
needed_disk_space:需要的磁盘空间
retention_time_seconds:保留时长,单位:秒
ingested_samples_per_second:每一秒钟摄取的样本数
bytes_per_sample:每个样本的字节大小
要降低摄取样本的速率,可以减少抓取的时间序列数量(减少目标数量或每个目标的序列数量),也可以增加抓取时间间隔。然而,减少系列的数量可能更有效,由于样品压缩在一个系列。
如果本地存储由于某种原因损坏,解决问题的最佳策略是关闭 Prometheus,然后删除整个存储目录。您也可以尝试删除单个块目录或 WAL 目录来解决问题。请注意,这意味着每个块目录会丢失大约两个小时的数据。同样,Prometheus 的本地存储并不打算作为长期可靠存储,外部解决方案可提供更长的保留时间和数据可靠性。
注意:
(1)Prometheus 的本地存储不支持非 POSIX 兼容文件系统,因为可能会发生无法恢复的损坏。不支持 NFS 文件系统(包括 AWS 的 EFS)。NFS 可以符合 POSIX 标准,但大多数实现都不符合 POSIX 标准。强烈建议使用本地文件系统,以确保可靠性。
(2)如果同时指定了时间和大小保留策略,则以先触发者为准。
(3)过期区块清理在后台进行,清除过期区块可能需要两个小时,区块必须完全过期后才会被移除。

 川公网安备51010802032098
川公网安备51010802032098