Prometheus客户端库提供了四种核心指标类型。目前,它们仅在客户端库(以启用针对特定类型的使用进行定制的API)和连接协议中有所区别。Prometheus 服务器尚未使用类型信息,而是将所有数据平铺为无类型的时间序列。未来可能会有所改变。
Counter(计数器)
计数器是一种累计指标,代表一个单调递增的计数器,其值只能在重启时增加或重置为零。例如,可以使用计数器来表示服务的请求数、完成的任务数或错误数。
不要使用计数器来表示可能会减少的值。例如,不要使用计数器来表示当前运行的进程数,而应使用 Gauge(仪表)。
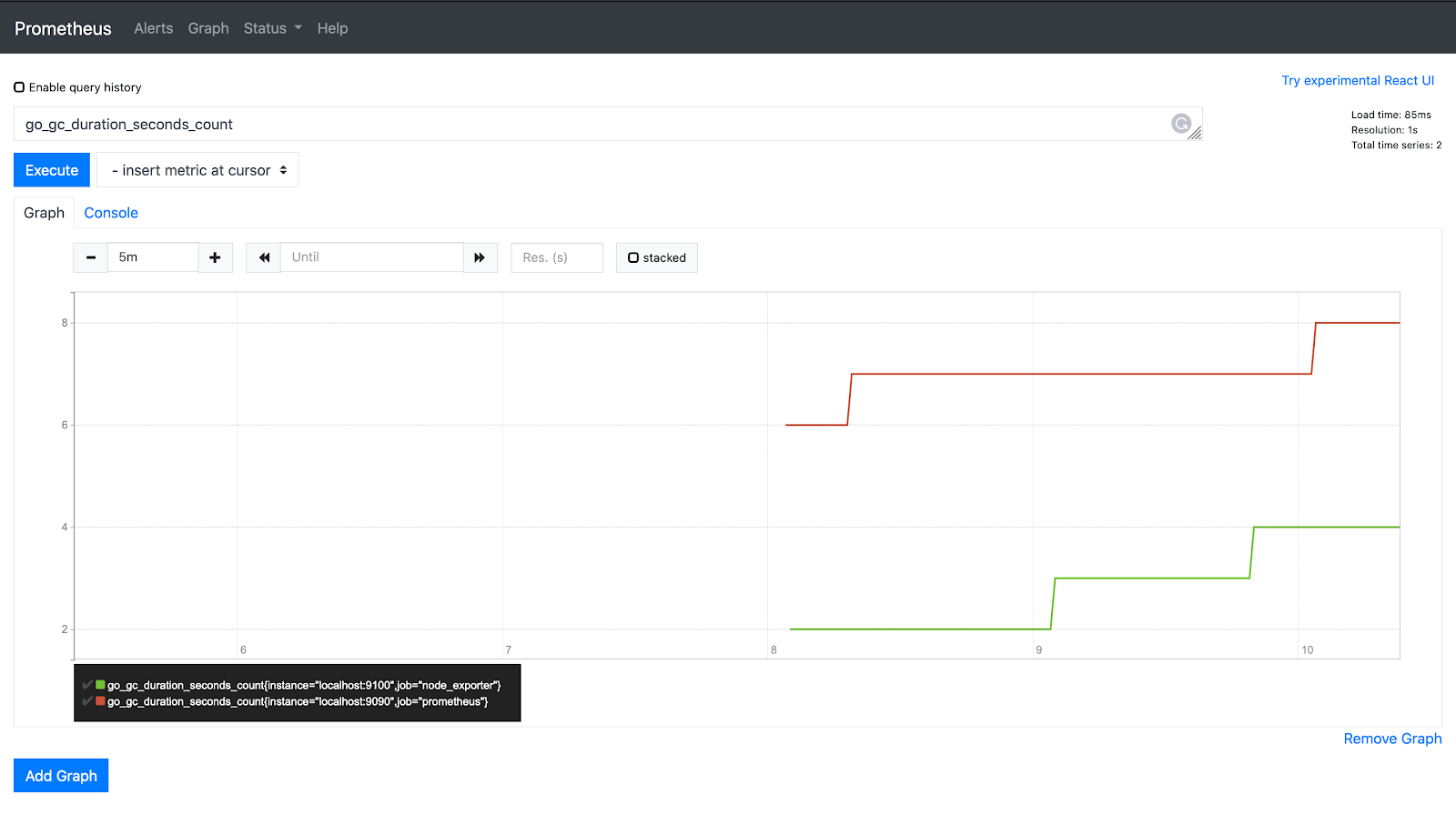
在查询栏中键入以下查询,然后点击执行:
go_gc_duration_seconds_count
效果图:
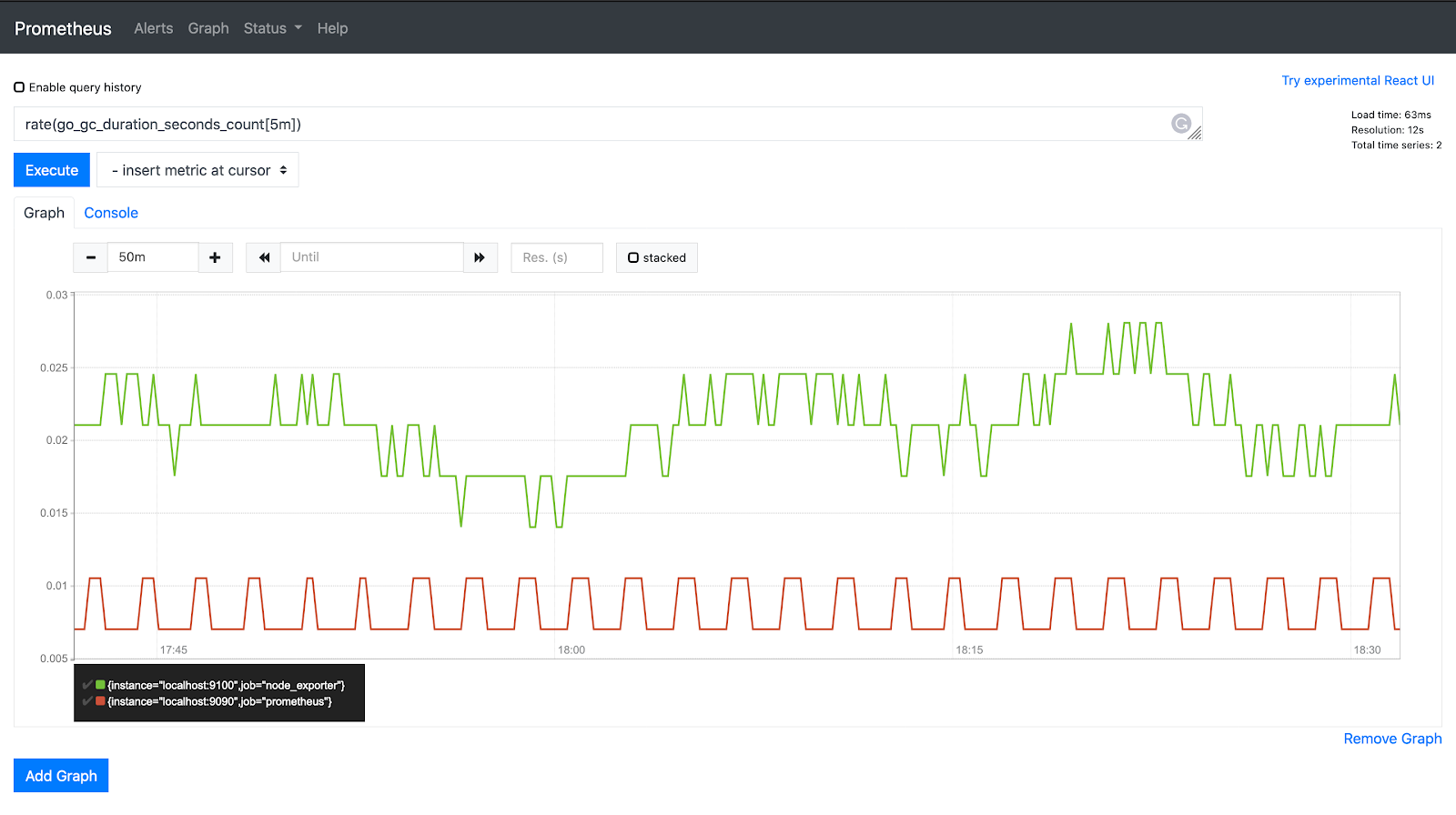
PromQL 中的 rate() 函数获取一段时间内的历史指标值,并计算该值每秒的增长速度。速率仅适用于计数器值:
rate(go_gc_duration_seconds_count[5m])
效果图:
Gauge(仪表)
仪表是一种指标,代表一个可以任意升降的单一数值。
仪表通常用于测量值,如温度或当前内存使用量,也可用于可上下波动的 "计数",如并发请求数。
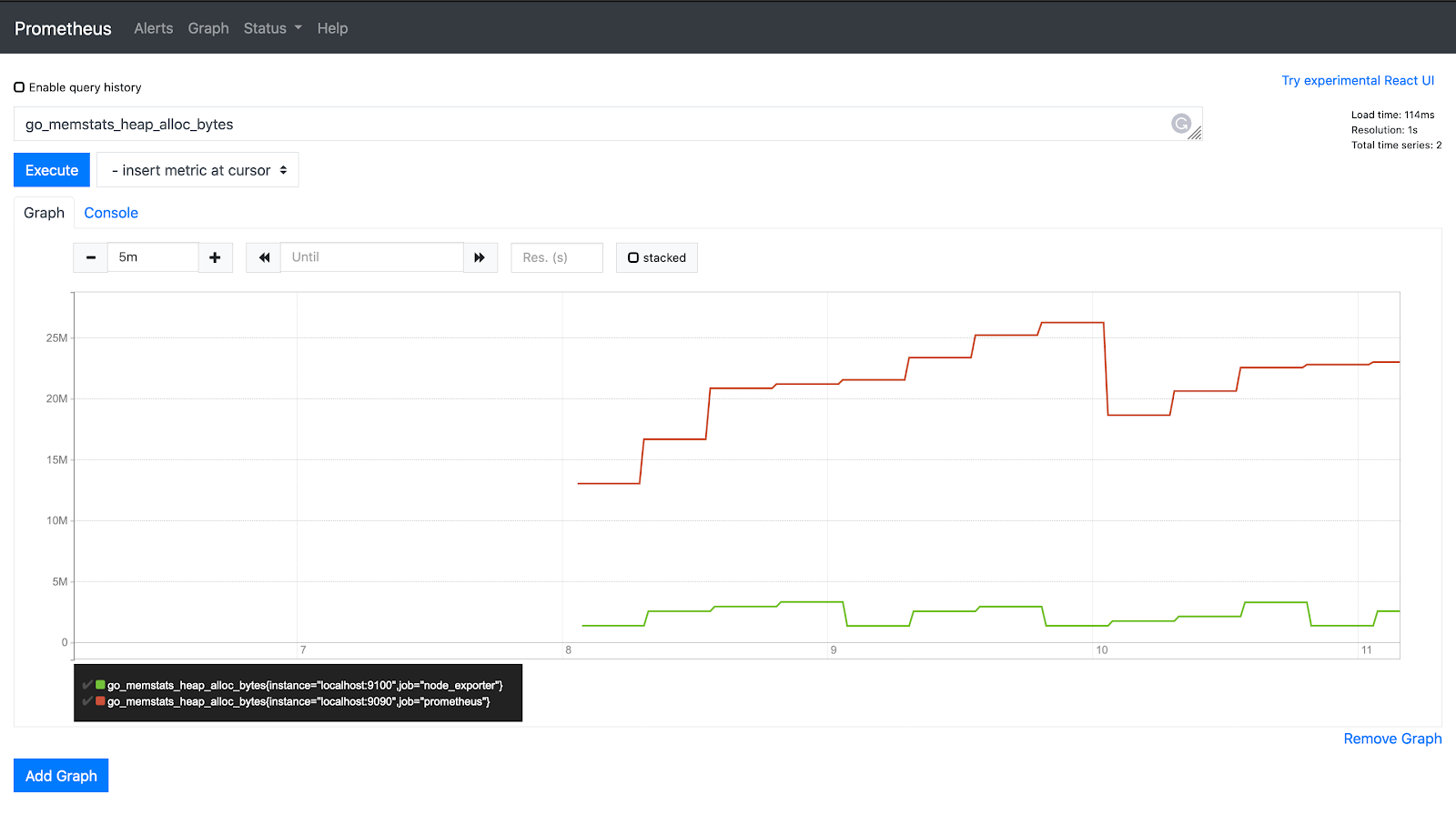
在查询栏中键入以下查询,然后点击执行:
go_memstats_heap_alloc_bytes
效果图:
PromQL 函数(如 max_over_time、min_over_time 和 avg_over_time)可用于测量指标。
Histogram(直方图)
什么是直方图?
直方图又称质量分布图,它是表示资料变化情况的一种主要工具。用直方图可以解析出资料的规则性,比较直观地看出产品质量特性的分布状态,对于资料分布状况一目了然,便于判断其总体质量分布情况。
直方图对观测值(通常是请求持续时间或响应大小等)进行采样,并按可配置的桶进行计数。它还提供所有观察值的总和。
基础指标名称为 <basename> 的直方图可在扫描过程中显示多个时间序列:
观察桶的累计计数器,显示为 <basename>_bucket{le="<pupper inclusive bound>"}
所有观测值的总和,显示为 <basename>_sum
已观察到的事件计数,显示为 <basename>_count(与上述 <basename>_bucket{le="+Inf"}相同)
使用 histogram_quantile() 函数可以计算直方图甚至直方图集合的量化值。直方图也适用于计算 Apdex 分数。在对桶进行操作时,请记住直方图是累积的。
注:从 Prometheus v2.40 版开始,试验性支持本地直方图。本机直方图只需要一个时间序列,其中除了观测值的总和与计数外,还包括一个动态的桶数。原生直方图的分辨率要高得多,而成本仅为原生直方图的一小部分。一旦本地直方图更接近于成为稳定的功能,我们将提供详细的文档。
与前两种指标类型相比,直方图是一种更为复杂的指标类型。直方图可用于根据桶值计算的任何计算值。桶的边界可由开发人员配置。一个常见的例子是回复请求所需的时间,称为延迟。
举例说明:假设我们想观察处理 API 请求所需的时间。直方图允许我们以桶为单位存储请求时间,而不是存储每个请求的请求时间。我们为所花费的时间定义桶,例如低于或等于 0.3、0.5、0.7、1 和 1.2。一旦计算出一个请求的耗时,就会将其添加到所有桶的计数中,这些桶的边界高于测量值。
比方说,端点 "/ping" 的请求 1 耗时 0.25 秒:
桶 | 次数 |
0 - 0.3 | 1 |
0 - 0.5 | 1 |
0 - 0.7 | 1 |
0 - 1 | 1 |
0 - 1.2 | 1 |
0 - +Inf | 1 |
注:默认添加 +Inf 桶,由于直方图是一个累积频率,所有大于该值的桶都会加上 1。
端点 "/ping" 的请求 2 耗时 0.4 秒 桶的计数值将如下:
Bucket | Count |
0 - 0.3 | 1 |
0 - 0.5 | 2 |
0 - 0.7 | 2 |
0 - 1 | 2 |
0 - 1.2 | 2 |
0 - +Inf | 2 |
由于 0.4 低于 0.5,因此在该界限以内的所有桶的计数都会增加。
让我们从 Prometheus UI 中探索一个直方图指标,并应用几个函数:
prometheus_http_request_duration_seconds_bucket{handler="/graph"}效果图:
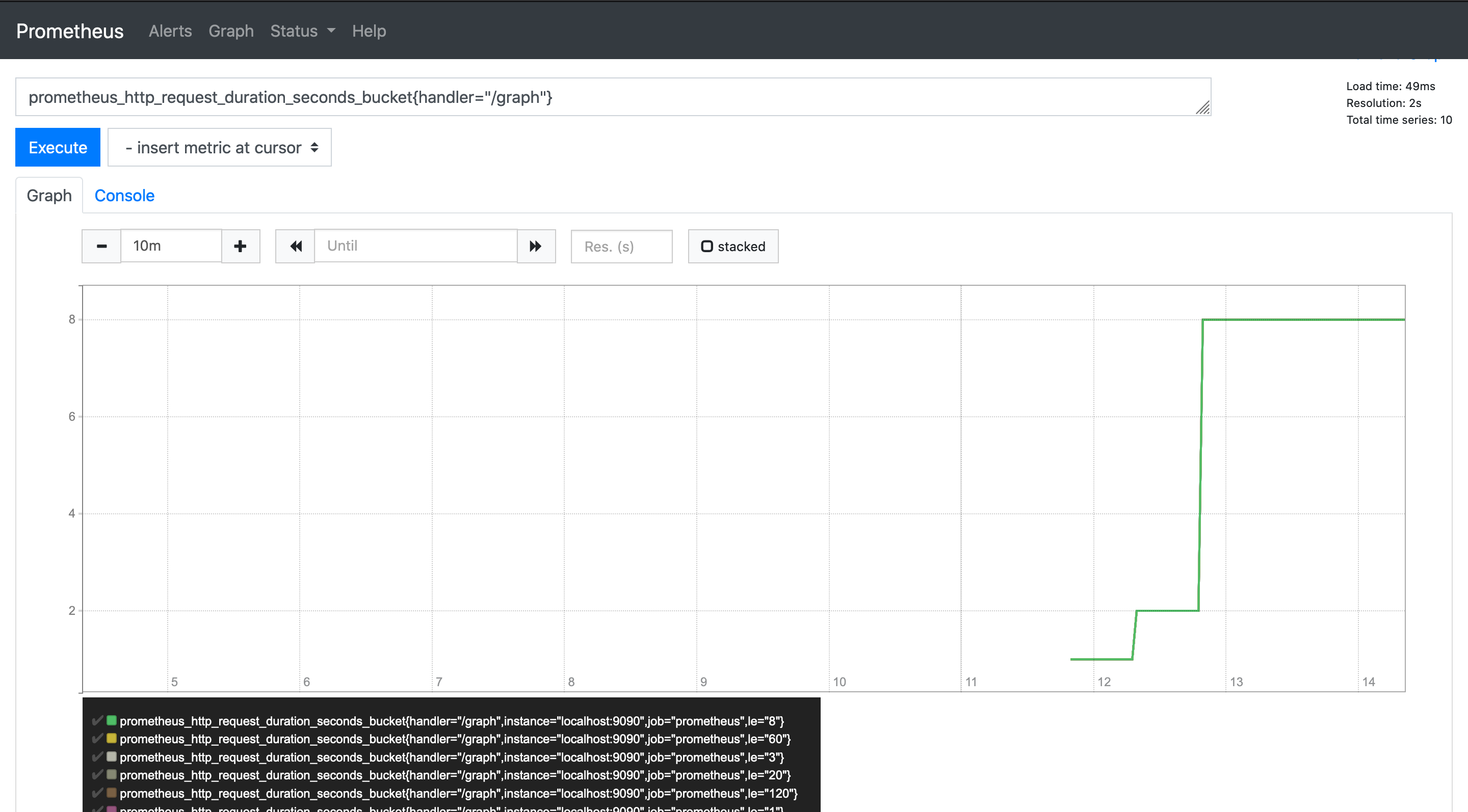
histogram_quantile() 函数可用于从直方图中计算定量值:
histogram_quantile(0.9,prometheus_http_request_duration_seconds_bucket{handler="/graph"})效果图:
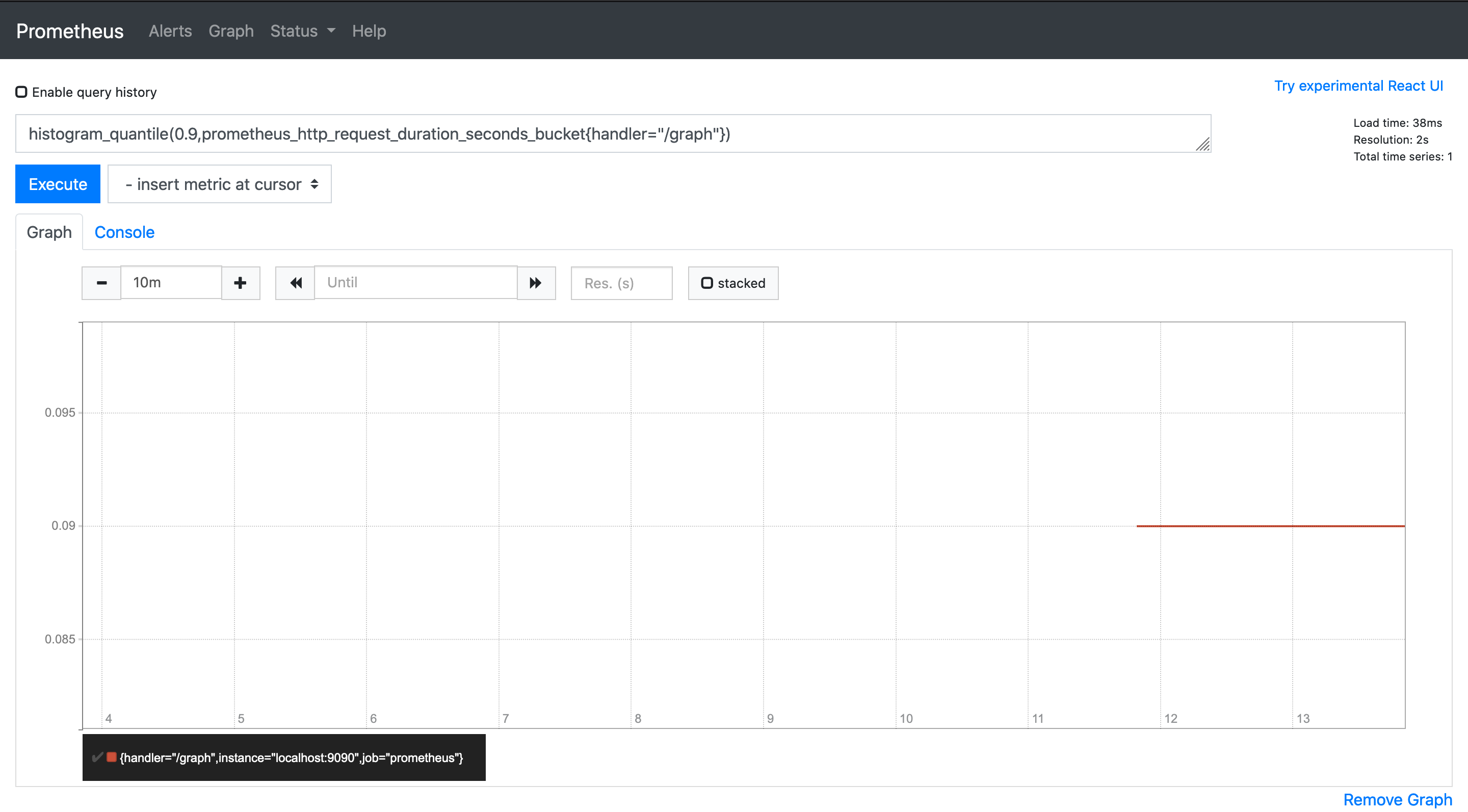
图中显示第 90 个百分位数是 0.09,要找到过去 5m 的直方图_四分位数,可以使用 rate() 和时间框架:
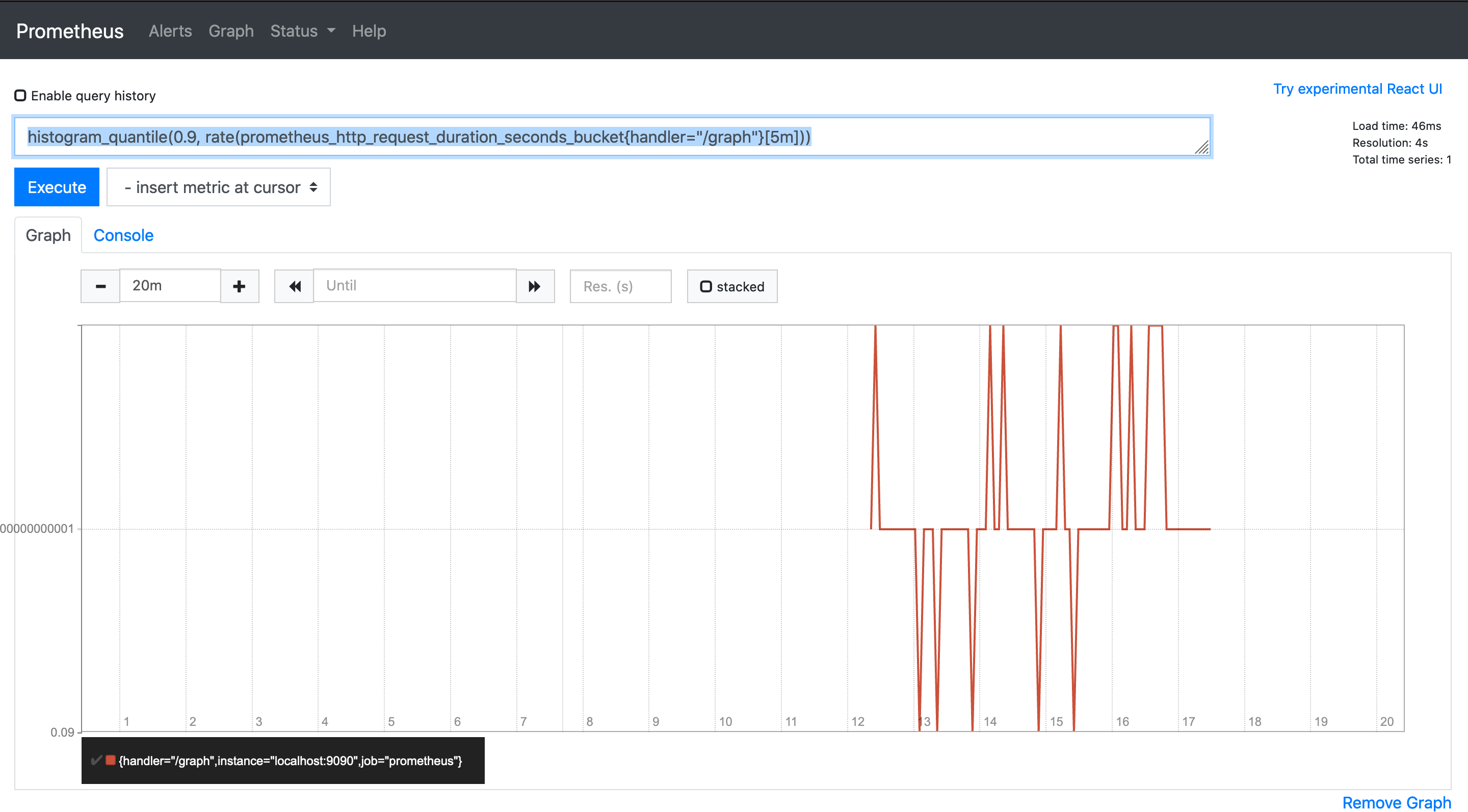
histogram_quantile(0.9, rate(prometheus_http_request_duration_seconds_bucket{handler="/graph"}[5m]))效果图:
Summary(汇总)
summary 指标类型通常用于记录某个操作的延迟、响应时间或其他类似可以聚合的统计信息。也可以测量事件,是直方图的替代品。它们的成本更低,但丢失的数据更多。它们是在应用程序级别计算的,因此无法汇总同一流程多个实例的指标。当事先不知道指标值的桶时,可以使用直方图,但强烈建议尽可能使用直方图而不是汇总。
summary 对观测值(通常是请求持续时间和响应大小等)进行采样。虽然它也提供观察值的总计数和所有观察值的总和,但它计算的是滑动时间窗口中可配置的量化值。
如基础指标名称为 <basename> 的 summary 会在扫描过程中显示多个时间序列:
观察到的事件的 φ-quantiles (0 ≤ φ ≤ 1),显示为 <basename>{quantile="<φ>"}
所有观测值的总和,显示为 <basename>_sum
已观察到事件的计数,显示为 <basename>_count
summary 指标类型包含以下组件:
count:记录观察到的事件总数。
sum:记录观察到的所有事件值的总和。
此外,summary 还可以生成以下两种类型的派生指标:
由于 summary 指标是预先聚合的,所以它们在查询和计算上更加高效。此外,它只存储了 count 和 sum,而不是完整的直方图数据,因此在存储上也更加节省空间。
在 PromQL 中,你可以使用 summary 类型的指标来执行各种聚合和计算操作,例如计算平均值、中位数或其他分位数等。
注意:summary 类型的指标通常在应用程序级别生成,而不是由 Prometheus 服务器本身生成。这意味着你需要在你的应用程序或服务中实现对 summary 指标的收集和报告。
以下是 summary 在实际使用中的一些场景:
HTTP 请求耗时统计:在微服务项目中,监测 HTTP 请求的耗时是非常重要的。通过使用 summary 指标,你可以记录每个请求的耗时,并计算中位数、90% 分位数等,以了解请求的整体性能和潜在的性能瓶颈。这有助于你及时发现并解决性能问题,提升用户体验。
服务响应时间监控:类似于 HTTP 请求耗时统计,summary 也可以用于监控服务的响应时间。通过记录服务响应的时间分布,你可以分析服务的稳定性和性能,并据此进行性能优化。
资源使用统计:summary 也可以用于记录和报告系统资源的使用情况,如 CPU 使用率、内存占用等。通过计算这些资源的分位数,你可以了解资源使用的整体趋势和潜在的资源瓶颈,从而进行合理的资源分配和优化。
错误统计和告警:通过将错误事件记录为 summary 指标,你可以计算错误率、错误发生的时间分布等,以便及时发现并解决系统错误。同时,你可以基于这些指标设置告警规则,当错误率达到一定阈值时触发告警,及时通知运维人员进行处理。



 川公网安备51010802032098
川公网安备51010802032098