负载均衡重试策略是指当客户端请求被分配到某一后端服务器,但该服务器未能成功处理请求(如返回错误、超时等情况)时,负载均衡器会按照一定的规则将该请求重新分配给其他服务器进行再次尝试处理的策略。这种策略的目的是为了提高请求的成功率,增强系统的容错性和可靠性。
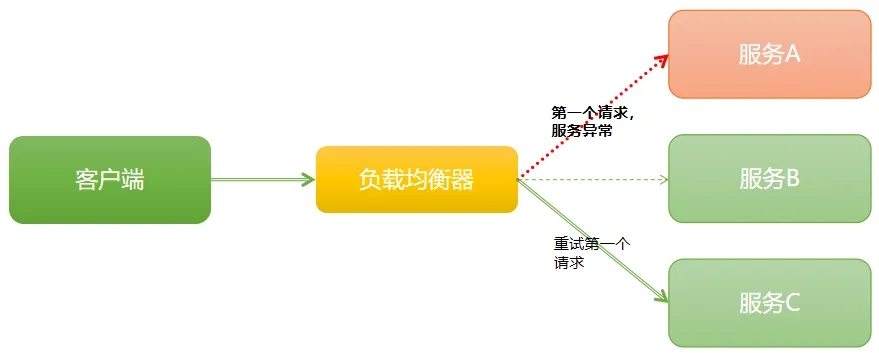
重试策略特点
错误恢复机制:重试策略提供了一种自动从部分服务器故障或临时错误中恢复的机制。当某个服务器出现短暂的网络抖动、过载或软件故障导致请求处理失败时,负载均衡器会将请求重试到其他健康的服务器上,从而有可能成功处理该请求。
基于条件触发:重试不是无条件进行的,通常是基于一定的条件触发。这些条件可能包括服务器返回的特定错误码(如 500 内部服务器错误、503 服务不可用)、请求超时等。只有当满足这些预设的失败条件时,才会启动重试流程。
可配置性:重试策略一般具有较高的可配置性。可以配置重试的次数,例如设置为最多重试 3 次;还可以配置重试的间隔时间,如每次重试之间间隔 1 秒,以避免对后端服务器造成过大的瞬时压力。
spring cloud 广告位
配置方式
在 application.properties 中,使用如下配置:
user.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RetryRule
将在名为 user 的客户端上开启重试策略。
源码分析
Ribbon 重试策略通过 com.netflix.loadbalancer.RetryRule 类实现,该类自身并没有提供负载均衡策略器,而是通过内部的 subRule(类型为 IRule,默认值为 RoundRobinRule 轮询策略) 成员来选择服务器。
(1)成员变量分析:
// 内置的负载均衡选择器,默认为 RoundRobinRule 轮询策略
IRule subRule = new RoundRobinRule();
// 最大重试时间,如果在该时间长度内还没有选择到服务器,则退出。单位:毫秒
long maxRetryMillis = 500L;
(2)构造方法分析:
public RetryRule() {
}
public RetryRule(IRule subRule) {
this.subRule = (IRule)(subRule != null ? subRule : new RoundRobinRule());
}
public RetryRule(IRule subRule, long maxRetryMillis) {
this.subRule = (IRule)(subRule != null ? subRule : new RoundRobinRule());
this.maxRetryMillis = maxRetryMillis > 0L ? maxRetryMillis : 500L;
}
通过构造函数设置 subRule(负载均衡规则,默认为 RoundRobinRule)和 maxRetryMillis,maxRetryMillis 默认为 500 毫秒。
(3)和前面的策略类似,重试逻辑主要在 choose 方法中:
// 该方法实现了一个选择服务器的方法,它在一定时间范围内(由 maxRetryMillis 决定)
// 不断尝试从一个子规则(subRule)中选择一个活着的服务器。
// 如果在给定时间内找到了满足条件的服务器,则返回该服务器,否则返回null。
public Server choose(ILoadBalancer lb, Object key) {
// 记录当前时间作为请求时间
long requestTime = System.currentTimeMillis();
// 计算截止时间,即请求时间加上最大重试时间(以毫秒为单位)
long deadline = requestTime + this.maxRetryMillis;
Server answer = null;
// 使用子规则尝试选择一个服务器
answer = this.subRule.choose(key);
// 如果初次选择的服务器为null或者不是活着的状态,
// 并且当前时间小于截止时间,则进入循环重试
if ((answer == null || !answer.isAlive()) && System.currentTimeMillis() < deadline) {
// 创建一个TimerTask定时任务,用来中断当前线程,后续介绍
InterruptTask task = new InterruptTask(deadline - System.currentTimeMillis());
// 判断当前线程是否被中断,配合 InterruptTask 任务,后续介绍
// 如果线程被 InterruptTask 中断,就不仅如此循环
while(!Thread.interrupted()) {
// 在循环中,不断使用子规则选择服务器,并检查服务器是否不为null且是活着的状态,
// 或者当前时间是否已经超过截止时间。如果满足条件,则跳出循环。
answer = this.subRule.choose(key);
if (answer != null && answer.isAlive() || System.currentTimeMillis() >= deadline) {
break;
}
// 如果不满足条件,则调用Thread.yield()让出 CPU 时间片,等待其他线程执行。
Thread.yield();
}
// 取消该定时器任务
task.cancel();
}
// 检查选择的服务器是否不为null且是活着的状态,如果是,则返回该服务器,否则返回null
return answer != null && answer.isAlive() ? answer : null;
}
上述 InterruptTask 类的代码:
// 一个 TimerTask
// TimerTask是 Java 中的一个抽象类,用于表示一个可以被Timer安排在指定时间执行的任务。
// 它允许开发者定义一个需要周期性执行或者在特定时间执行的任务,
// 并通过Timer类来管理任务的调度。
public class InterruptTask extends TimerTask {
static Timer timer = new Timer("InterruptTimer", true);
protected Thread target = null;
public InterruptTask(long millis) {
// 目标线程,就是重试策略哪个线程
this.target = Thread.currentThread();
// 表示从调用schedule方法开始,经过delay毫秒后执行task
timer.schedule(this, millis);
}
public InterruptTask(Thread target, long millis) {
this.target = target;
timer.schedule(this, millis);
}
public boolean cancel() {
try {
return super.cancel();
} catch (Exception var2) {
return false;
}
}
public void run() {
if (this.target != null && this.target.isAlive()) {
// 中断目标线程
this.target.interrupt();
}
}
}
上面代码中,timer.schedule(this, millis) 语句的 millis 为 deadline - System.currentTimeMillis(),计算截止时间减去当前时间,为了保证在 maxRetryMillis 最大重试时间后中断重试策略线程。
重试策略优缺点
优点
提高请求成功率:通过将失败的请求重新分配到其他服务器,增加了请求成功处理的机会。特别是在服务器集群中存在个别服务器临时出现问题的情况下,能够有效减少因服务器故障导致的请求丢失或错误,提升了用户体验和系统的整体可靠性。
增强系统容错性:使得系统能够在一定程度上容忍服务器的故障和不稳定因素。对于一个复杂的分布式系统,其中的服务器可能会因为各种原因出现短暂的异常,重试策略可以帮助系统在这种情况下保持正常的服务能力。
缺点
可能导致额外负载:如果不加限制地进行重试,尤其是在服务器集群整体负载较高或者后端服务器出现系统性问题(如数据库故障)时,重试可能会给其他服务器带来额外的负载压力。过多的重试请求可能会使原本正常的服务器也陷入过载状态。
增加请求处理时间的不确定性:重试会导致请求的处理时间变得不确定。如果每次重试都需要等待一定的时间间隔,再加上服务器处理请求本身的时间,那么对于一些对响应时间敏感的应用,可能会影响用户体验。而且,如果重试多次后仍然失败,总的请求处理时间会大大延长。
复杂的错误处理和状态管理:需要考虑如何正确处理重试过程中可能出现的各种情况。例如,在重试时,如何区分是服务器暂时故障还是请求本身存在问题;如何避免因为重试而导致的数据不一致等问题。同时,还需要对重试的状态进行管理,如记录已经重试的次数等。
spring cloud 广告位
适用场景
对请求成功率要求较高的应用:如金融交易系统、电子商务系统中的支付环节等。这些场景下,即使遇到服务器暂时的问题,也需要尽力确保请求能够成功处理,以避免用户资金损失或交易失败。通过重试策略,可以在一定程度上保障交易的成功率。
存在临时故障可能的服务器环境:当后端服务器可能会因为网络波动、硬件资源短暂耗尽(如 CPU 峰值使用)或软件的小故障(如某个服务的短暂重启)等情况出现临时错误时,重试策略非常适用。例如,在云计算环境中的微服务架构,服务实例可能会因为自动伸缩或资源争抢等情况出现短暂不可用,此时重试策略可以帮助提高系统整体的稳定性。
非实时性或对响应时间不太敏感的应用:对于一些对响应时间要求不是特别严格的应用,如数据备份系统、日志收集系统等,重试策略带来的响应时间不确定性的影响相对较小。这些系统更关注数据的完整性和最终的成功处理,适当的重试可以确保数据能够被正确存储或传输。

 川公网安备51010802032098
川公网安备51010802032098