前面介绍了 MySQL 中错误处理,我们通过 DECLARE HANDLER 命令来定义了当 MySQL 警告或错误等指定事件发生时,存储程序应采取的操作。
下面是 DECLARE HANDLER 命令的语法:
DECLARE {CONTINUE | EXIT} HANDLER FOR
{SQLSTATE sqlstate_code| MySQL error code| condition_name}
handler_actions
注意,错误处理程序必须在变量或游标声明之后定义,这是有道理的,因为错误处理程序经常访问局部变量或对游标执行操作(如关闭游标)。另外,处理程序还必须在任何可执行语句之前声明。
错误处理程序声明有三个主要部分:
(1)处理程序类型(CONTINUE、EXIT)
(2)处理程序条件(SQLSTATE、MySQL 错误代码、命名条件)
(3)处理程序操作
处理程序类型
条件处理程序有两种类型:
注意:无论是哪种情况,处理程序中定义的任何语句(处理程序操作)都会在 EXIT 或 CONTINUE 发生之前运行。
示例一:下面存储过程创建了一条用户记录,并尝试从容处理指定用户已经存在的情况:
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_user`(
IN in_id INT,
IN in_name VARCHAR(50),
IN in_age INT,
IN in_sex VARCHAR(1)
)
BEGIN
-- 声明一个状态变量,记录重复插入的状态
DECLARE duplicate_key INT DEFAULT 0;
-- 这个 BEGIN-END 块包含 INSERT 语句,它将尝试插入用户记录
-- 该代码块包括 EXIT 处理程序,如果出现 1062 错误,它将终止该代码块
BEGIN
-- 如果出现 Duplicate key 错误,处理程序将设置 duplicate_key 变量的值为 1,,并且终止当前 BEGIN 代码块
DECLARE EXIT HANDLER FOR 1062 SET duplicate_key=1;
-- 插入用户信息
INSERT INTO `user`(`id`, `name`, `age`, `sex`) VALUES (in_id, in_name, in_age, in_name);
-- 这一行仅在 EXIT 处理程序没有触发的情况下执行,并向用户报告成功
-- 如果处理程序触发,则程序块被终止,这一行永远不会被执行
SELECT CONCAT('Department ID=', in_id, ' created') as "Result";
END;
-- 这一行将继续执行,我们将检查 duplicate_key 变量的值
-- 如果处理程序已触发(duplicate_key 等于 1),则通知用户插入失败
IF duplicate_key=1 THEN
SELECT CONCAT('Failed to insert ID=', in_id, ': duplicate key') as "Result";
END IF;
END
调用存储过程,输出如下:
-- 插入非重复KEY
mysql> call insert_user(3, 'Test', 30, 0);
+-------------------------+
| Result |
+-------------------------+
| Department ID=3 created |
+-------------------------+
1 row in set (0.05 sec)
Query OK, 0 rows affected (0.01 sec)
-- 插入重复KEY
mysql> call insert_user(3, 'Test', 30, 0);
+--------------------------------------+
| Result |
+--------------------------------------+
| Failed to insert ID=3: duplicate key |
+--------------------------------------+
1 row in set (0.04 sec)
Query OK, 0 rows affected (0.00 sec)
mysql 广告位
示例二:在这个示例中,当处理程序触发时,将继续执行紧接 INSERT 语句之后的语句。该 IF 语句会检查处理程序是否触发,如果触发,则显示失败消息。否则,将显示成功消息。
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_user`(
IN in_id INT,
IN in_name VARCHAR(50),
IN in_age INT,
IN in_sex VARCHAR(1)
)
BEGIN
-- 声明一个状态变量,记录重复插入的状态
DECLARE duplicate_key INT DEFAULT 0;
-- 如果出现 Duplicate key 错误,处理程序将设置 duplicate_key 变量的值为 1
DECLARE CONTINUE HANDLER FOR 1062 SET duplicate_key=1;
-- 插入用户信息
INSERT INTO `user`(`id`, `name`, `age`, `sex`) VALUES (in_id, in_name, in_age, in_name);
-- 这一行将继续执行,我们将检查 duplicate_key 变量的值
IF duplicate_key=1 THEN
-- 如果处理程序已触发,则通知用户插入不成功
SELECT CONCAT('Failed to insert ID=', in_id, ': duplicate key') as "Result";
ELSE
-- 如果处理程序没有出发,则提示插入成功
SELECT CONCAT('Department ID=', in_id, ' created') as "Result";
END IF;
END
调用存储过程,输出如下:
-- 插入非重复KEY
mysql> call insert_user(4, 'Test', 30, 0);
+-------------------------+
| Result |
+-------------------------+
| Department ID=4 created |
+-------------------------+
1 row in set (0.06 sec)
Query OK, 0 rows affected (0.01 sec)
-- 插入重复的KEY
mysql> call insert_user(4, 'Test', 30, 0);
+--------------------------------------+
| Result |
+--------------------------------------+
| Failed to insert ID=4: duplicate key |
+--------------------------------------+
1 row in set (0.06 sec)
Query OK, 0 rows affected (0.00 sec)
怎样选择 EXIT 或 CONTINUE?
选择创建 EXIT 处理程序还是创建 CONTINUE 处理程序,主要是基于程序流程控制的考虑。
EXIT 处理程序将从声明它的程序块中退出,这就排除了执行该程序块(或整个存储过程)中任何其他语句的可能性。这种类型的处理程序最适用于无法继续处理的灾难性错误。
CONTINUE 处理程序允许执行后续语句。一般情况下,您将检测到处理程序已触发(通过在处理程序中设置的某种形式的状态变量),并确定最合适的操作过程。这种类型的处理程序最适合在异常发生时执行一些替代处理。
处理程序条件
处理程序条件定义了在何种情况下将调用/触发处理程序。这种情况总是与错误条件相关联,但对于如何定义错误,有三种选择:
(1)使用 MySQL 错误代码。
(2)使用 ANSI 标准 SQLSTATE 代码。
(3)使用命名条件,你可以定义自己的命名条件,或使用内置条件 SQLEXCEPTION、SQLWARNING 和 NOT FOUND。
MySQL 有自己的一组错误代码,它们是 MySQL 服务器独有的。处理程序条件如果不加限定地引用数字代码,就是引用 MySQL 的错误代码。例如,当遇到 MySQL 错误代码 1062(键值重复)时,以下处理程序将触发:
DECLARE CONTINUE HANDLER FOR 1062 SET duplicate_key=1;
SQLSTATE 错误代码由 ANSI 标准定义,与数据库无关,也就是说,无论底层数据库是什么,它们的值都是一样的。例如,当遇到键值重复错误时,Oracle、SQL Server、DB2 和 MySQL 将始终报告相同的 SQLSTATE 值(23000)。每个 MySQL 错误代码都有一个关联的 SQLSTATE 代码,但这种关系并不是一一对应的;有些 SQLSTATE 代码与许多 MySQL 代码相关联;HY000 是一个通用 SQLSTATE 代码,用于引发没有特定关联 SQLSTATE 代码的 MySQL 代码。
当遇到 SQLSTATE 23000(键值重复)时,将触发以下处理程序:
DECLARE CONTINUE HANDLER FOR SQLSTATE '23000' SET duplicate_key=1;
使用 SQLSTATE 还是 MySQL 错误代码?
从理论上讲,使用 SQLSTATE 代码会让你的代码更容易移植到其他数据库平台,因此似乎是最好的选择。不过,在编写 MySQL 存储程序时,使用 MySQL 错误代码而不是 SQLSTATE 代码有很多原因:
(1)实际上,你不太可能将存储程序转移到另一个 RDBMS,因为不同的 RDBMS 之间存在不兼容问题。
(2)并非所有 MySQL 错误代码都与 SQLSTATE 对应。虽然每个 MySQL 错误代码都与某些 SQLSTATE 错误代码相关联,但通常都是非特定的通用 SQLSTATE(如 HY000)错误代码。
注意,当 MySQL 客户端遇到错误时,它会同时报告 MySQL 错误代码和相关的 SQLSTATE 代码,如以下输出所示:
mysql> CALL nosuch_sp( );
ERROR 1305 (42000): PROCEDURE sqltune.nosuch_sp does not exist
上面错误消息中,MySQL 错误代码是 1305,SQLSTATE 代码是 42000。
下面表列出了在 MySQL 存储程序中可能遇到的一些错误代码及其 SQLSTATE 对应代码。许多 MySQL 错误代码映射到相同的 SQLSTATE 代码(例如,许多映射到 HY000),这就是为什么你宁愿牺牲可移植性,也要在错误处理程序中使用 MySQL 错误代码而不是 SQLSTATE 代码:
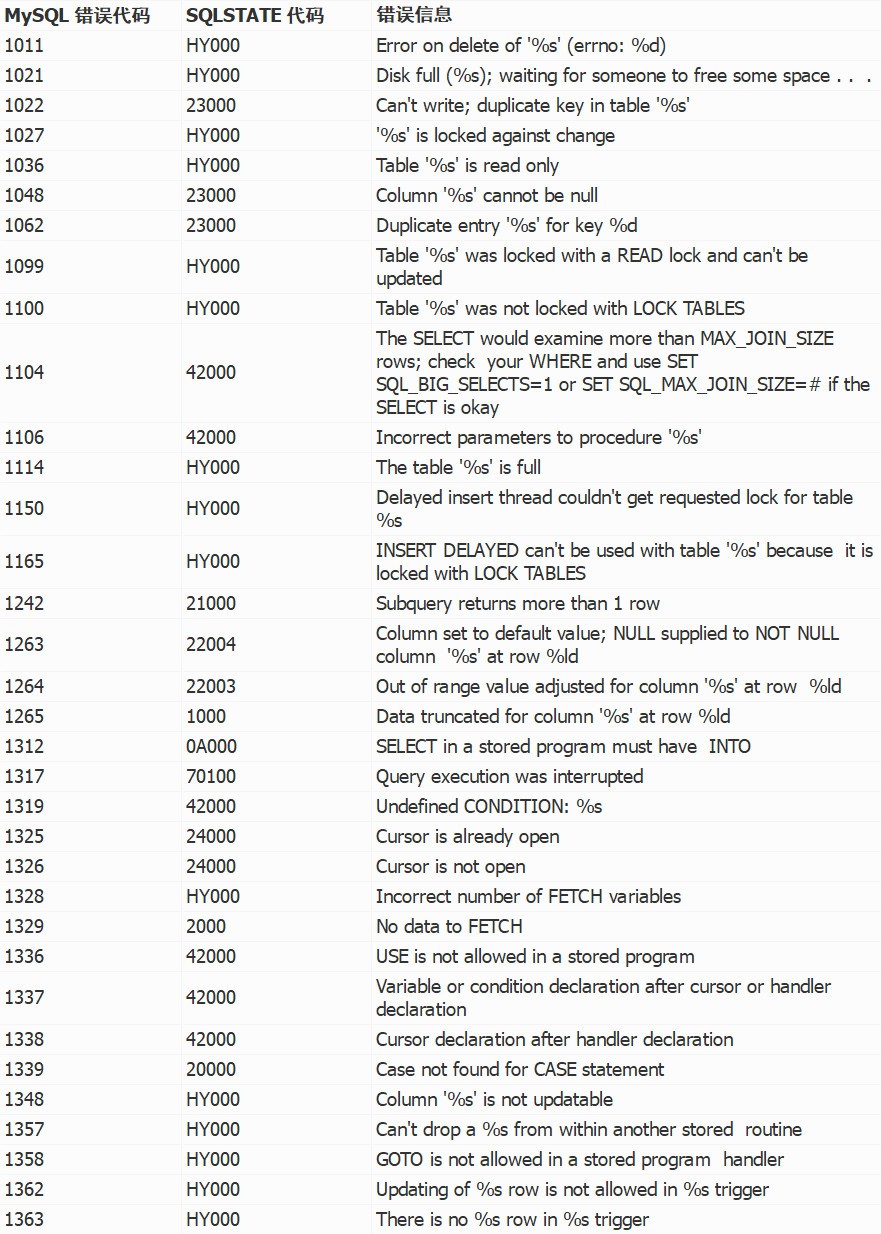
您可以在 MySQL 参考手册附录 B 中找到完整的最新错误代码列表,该手册可在 http://dev.mysql.com/doc/ 上在线获取。
处理程序示例
下面是一些处理程序声明示例:
(1)如果出现任何错误条件(NOT FOUND 除外),在设置 l_error=1 后继续执行:
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION
SET l_error=1;
(2)如果出现任何错误条件(NOT FOUND 除外),在发出 ROLLBACK 语句和错误信息后退出当前程序块或存储程序:
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
ROLLBACK;
SELECT 'Error occurred - terminating';
END;
(3)如果遇到 MySQL 错误 1062(键值重复),则在执行 SELECT 语句(为调用程序生成一条信息)后继续执行:
DECLARE CONTINUE HANDER FOR 1062
SELECT 'Duplicate key in index';
(4)如果遇到 SQLSTATE 23000(键值重复),则在执行 SELECT 语句(为调用程序生成一条消息)后继续执行:
DECLARE CONTINUE HANDER FOR SQLSTATE '23000'
SELECT 'Duplicate key in index';
(5)当获取游标或 SQL 没有检索到任何值时,在设置 l_done=1 后继续执行:
DECLARE CONTINUE HANDLER FOR NOT FOUND
SET l_done=1;
(6)与上例相同,只是使用 SQLSTATE 变量而不是命名条件指定:
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000'
SET l_done=1;
(7)与前两个示例相同,只是使用了 MySQL 错误代码变量,而不是命名条件或 SQLSTATE 变量:
DECLARE CONTINUE HANDLER FOR 1329
SET l_done=1;
mysql 广告位
处理程序优先级
MySQL 允许你用 MySQL 错误代码、SQLSTATE 错误或命名条件(如 SQLEXCEPTION)来定义处理程序条件。因此,你可以在一个存储程序中定义多个处理程序,当发生特定错误时,这些处理程序都可以触发。然而,只有一个处理程序可以触发错误,而且 MySQL 已明确定义了在这种情况下决定处理程序优先级的规则。
例如,下面我们声明了三个不同的处理程序,如果发生键值重复错误,每个处理程序都有资格执行。哪个处理程序会被执行?答案是执行最特殊的处理程序。
-- 定义多个处理程序
-- MySQL 错误代码优先级最高
DECLARE EXIT HANDLER FOR 1062 SELECT 'MySQL error 1062 encountered';
-- SQLSTATE 优先级次之
DECLARE EXIT HANDLER FOR SQLSTATE '23000' SELECT 'SQLSTATE 23000';
-- 优先级最低
DECLARE EXIT HANDLER FOR SQLEXCEPTION SELECT 'SQLException encountered';
-- 插入数据
INSERT INTO `user`(`id`, `name`, `age`, `sex`) VALUES (in_id, in_name, in_age, in_name);
注意:
(1)基于 MySQL 错误代码的处理程序是最具体的处理程序类型,因为错误条件总是与单个 MySQL 错误代码相对应。
(2)SQLSTATE 代码有时会映射到多个 MySQL 错误代码,因此它们的具体程度较低。因为,一个 SQLSTATE 可能对于多个 MYSQL 错误,不确定和具体,不能明确知道具体原因。
(3)SQLEXCEPTION 和 SQLWARNING 等一般情况则完全不具体。
因此,MySQL 错误代码优先于 SQLSTATE 异常,而 SQLSTATE 异常又优先于 SQLEXCEPTION 条件。
通过这种严格定义的优先级,我们可以为意外情况定义一个通用处理程序,同时为那些我们很容易预料到的情况创建一个特定的处理程序。因此,下面示例中,如果发生了灾难性事件,第一个处理程序将被调用,而第二个处理程序将在更有可能发生的情况下触发,即有人试图在你的数据库中创建重复行:
-- 重复键错误处理
DECLARE EXIT HANDLER FOR 1062
SELECT 'Attempt to create a duplicate entry occurred';
-- 通用的错误处理
DECLARE EXIT HANDLER FOR SQLEXCEPTION
SELECT 'Unexpected error occurred - make sure Fred did not drop your tables again';
条件处理程序的范围
处理程序的范围决定了该处理程序覆盖了存储程序中的哪些语句。从本质上讲,处理程序的作用域与存储程序变量的作用域相同:处理程序适用于定义它的程序块中的所有语句,包括嵌套程序块中的任何语句。此外,存储程序中的处理程序还包括在任何可能被第一个程序调用的存储程序中执行的语句,除非该程序声明了自己的处理程序。
示例一:下面例子中,处理程序将在 INSERT 语句执行时调用(因为它违反了 NOT NULL 约束)。处理程序触发的原因是 INSERT 语句与处理程序位于同一程序块中,尽管 INSERT 语句位于嵌套程序块中。
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_user`(
IN in_id INT,
IN in_name VARCHAR(50),
IN in_age INT,
IN in_sex VARCHAR(1)
)
BEGIN
-- 定义处理器
DECLARE CONTINUE HANDLER FOR 1048 SELECT 'Attempt to insert a null value';
-- 嵌套代码块
BEGIN
INSERT INTO `user`(`id`, `name`, `age`, `sex`) VALUES (in_id, null, in_age, in_name);
END;
END
调用存储过程,输出如下:
mysql> call insert_user(4, 'Test', 30, 0);
+--------------------------------+
| Attempt to insert a null value |
+--------------------------------+
| Attempt to insert a null value |
+--------------------------------+
1 row in set (0.03 sec)
Query OK, 0 rows affected (0.01 sec)
示例二:下面示例中,处理程序不会被调用,因为处理程序的作用域仅限于嵌套代码块,而 INSERT 语句发生在嵌套代码块之外。
BEGIN
BEGIN
DECLARE CONTINUE HANDLER FOR 1216 select
'Foreign key constraint violated';
END;
INSERT INTO departments (department_name,manager_id,location)
VALUES ('Elbonian HR','Catbert','Catbertia');
END;
调用存储过程,输出如下:
mysql> call insert_user(4, 'Test', 30, 0);
ERROR 1048 (23000): Column 'name' cannot be null
示例三:处理程序作用域可扩展到在处理程序作用域内调用的任何存储过程或函数。这意味着,如果一个存储程序调用另一个存储程序,调用程序中的处理程序可以捕获被调用程序中出现的错误。下面的处理程序捕获了在 sub_procedure( ) 中出现的空值异常。
-- 存储过程1,被另一个存储过程调用
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_user`(
IN in_id INT,
IN in_name VARCHAR(50),
IN in_age INT,
IN in_sex VARCHAR(1)
)
BEGIN
-- 会触发 not null 空置错误
INSERT INTO `user`(`id`, `name`, `age`, `sex`) VALUES (in_id, null, in_age, in_name);
END
-- 存储过程2
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_user_ext`(
IN in_id INT,
IN in_name VARCHAR(50),
IN in_age INT,
IN in_sex VARCHAR(1),
IN in_phone varchar(200),
IN in_email varchar(200))
myBegin:BEGIN
DECLARE exe_state INT DEFAULT 0;
-- 定义处理器
DECLARE CONTINUE HANDLER FOR 1048 SET exe_state=1;
-- 调用 insert_user 过程插入用户基本信息
CALL insert_user(in_id, in_name, in_age, in_sex);
IF exe_state = 1 THEN
-- 直接输出错误消息
SELECT '插入用户信息失败' as Error;
-- 离开 BEGIN 语句块
LEAVE myBegin;
END IF;
-- 更新,添加电话和邮件
UPDATE `user` SET phont=in_phone, email=in_email WHERE id=in_id;
END myBegin
调用存储过程,输出如下:
mysql> call insert_user_ext(4, 'Test', 30, 0, '15881002233', 'test@gmail.com');
+------------------+
| Error |
+------------------+
| 插入用户信息失败 |
+------------------+
1 row in set (0.03 sec)
Query OK, 0 rows affected (0.00 sec)
当然,存储过程中的处理程序将覆盖调用存储过程中存在的处理程序的作用域。对于一个特定的错误条件,只能激活一个处理程序。

 川公网安备51010802032098
川公网安备51010802032098