在 MongoDB 中,可以使用MapReduce来进行复杂的数据聚合和计算操作。MapReduce 是一种分布式计算模型,它将大规模的数据集分为多个小的数据块,然后在每个数据块上进行映射(Map)和归约(Reduce)操作,最后将结果合并起来。
MapReduce的基本过程如下:
映射(Map)阶段:将输入数据集映射为键-值对的形式。在这个阶段,我们需要定义一个映射函数,它将输入的数据转换为键-值对。
归约(Reduce)阶段:将映射阶段的输出进行归约操作,生成最终的结果。在这个阶段,我们需要定义一个归约函数,它将键-值对进行聚合操作,生成最终的结果。
合并(Merge)阶段:将多个归约阶段的结果合并为一个最终的结果。
mapReduce() 方法
在 MongoDB 中,可以使用 mapReduce() 方法来执行 MapReduce 操作。mapReduce() 方法的基本语法如下:
db.collection.mapReduce(
function() { emit(key,value); }, // map 函数
function(key,values) { return reduceFunction; }, // reduce 函数
{
out: <collection>, // 输出,可选,将结果汇入指定表
query: <document>, // 可选,筛选数据的条件,筛选的数据送入map
sort: <document>, // 排序完后,送入 map
limit: <number>, // 限制送入 map 的文档数
finalize: <function>, // 可选,修改 reduce 的结果后进行输出
scope: <document>, // 可选,指定 map、reduce、finalize 的全局变量
jsMode: <boolean>, // 可选,默认 false。在 mapreduce 过程中是否将数 据转换成 bson 格式
verbose: <boolean>, // 可选,是否在结果中显示时间,默认 false
bypassDocumentValidation: <boolean> // 可选,是否略过数据校验
}
)
mongodb广告位
mapReduce() 简单示例
假设我们有一个名为 orders 的集合,其中包含了订单信息,我们可以使用 MapReduce 来计算每个客户的订单总金额。
准备数据
下面将准备一点订单数据,如下:
db.orders.insertOne({ order_id:1, cust_id:100, amount:10, status:'A' });
db.orders.insertOne({ order_id:2, cust_id:100, amount:15, status:'A' });
db.orders.insertOne({ order_id:3, cust_id:100, amount:13, status:'A' });
db.orders.insertOne({ order_id:4, cust_id:100, amount:12, status:'A' });
db.orders.insertOne({ order_id:5, cust_id:200, amount:22, status:'B' });
db.orders.insertOne({ order_id:6, cust_id:200, amount:32, status:'B' });
db.orders.insertOne({ order_id:7, cust_id:200, amount:21, status:'B' });
db.orders.insertOne({ order_id:8, cust_id:200, amount:28, status:'B' });
db.orders.insertOne({ order_id:9, cust_id:300, amount:45, status:'A' });
db.orders.insertOne({ order_id:10, cust_id:300, amount:65, status:'A' });
db.orders.insertOne({ order_id:11, cust_id:300, amount:10, status:'B' });
db.orders.insertOne({ order_id:12, cust_id:400, amount:101, status:'B' });
db.orders.insertOne({ order_id:13, cust_id:400, amount:22, status:'A' });
db.orders.insertOne({ order_id:14, cust_id:500, amount:43, status:'B' });
执行上面语句后,数据如下:
> db.orders.find()
{ "_id" : ObjectId("650934a59e088205aea0bf7d"), "order_id" : 1, "cust_id" : 100, "amount" : 10, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf7e"), "order_id" : 2, "cust_id" : 100, "amount" : 15, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf7f"), "order_id" : 3, "cust_id" : 100, "amount" : 13, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf80"), "order_id" : 4, "cust_id" : 100, "amount" : 12, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf81"), "order_id" : 5, "cust_id" : 200, "amount" : 22, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf82"), "order_id" : 6, "cust_id" : 200, "amount" : 32, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf83"), "order_id" : 7, "cust_id" : 200, "amount" : 21, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf84"), "order_id" : 8, "cust_id" : 200, "amount" : 28, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf85"), "order_id" : 9, "cust_id" : 300, "amount" : 45, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf86"), "order_id" : 10, "cust_id" : 300, "amount" : 65, "status" : "A" }
{ "_id" : ObjectId("650934a59e088205aea0bf87"), "order_id" : 11, "cust_id" : 300, "amount" : 10, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf88"), "order_id" : 12, "cust_id" : 400, "amount" : 101, "status" : "B" }
{ "_id" : ObjectId("650934a59e088205aea0bf89"), "order_id" : 13, "cust_id" : 400, "amount" : 22, "status" : "A" }
{ "_id" : ObjectId("650934a69e088205aea0bf8a"), "order_id" : 14, "cust_id" : 500, "amount" : 43, "status" : "B" }
统计每个客户的订单总金额
> db.orders.mapReduce(
function() {
emit(this.cust_id, this.amount);
},
function(key, values) {
return Array.sum(values);
},
{
query: { status:"A" },
out: "order_totals",
}
)
{ "result" : "order_totals", "ok" : 1 }
查看结果
> db.order_totals.find()
{ "_id" : 100, "value" : 50 }
{ "_id" : 300, "value" : 110 }
{ "_id" : 400, "value" : 22 }
上述示例中,我们定义了一个映射(Map)函数,将订单文档中的 cust_id 作为键,amount 作为值进行映射。然后定义了一个 Reduce 函数,对相同键的值进行求和操作(Array.sum 语句)。最后,我们指定了输出集合为 order_totals,将计算结果存储在这个集合中。
执行流程如下图:
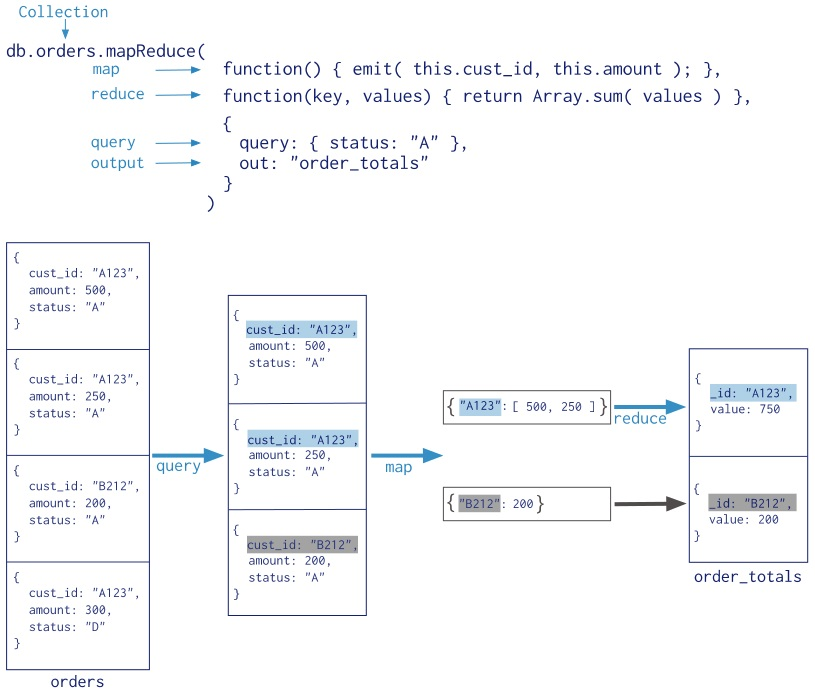
注意:MapReduce 是一种强大而灵活的数据处理方式,但它的性能相对较低。在实际使用中,应该根据具体的需求和数据量来选择是否使用 MapReduce。对于一些简单的聚合操作,可以考虑使用聚合管道(Aggregation Pipeline)来替代 MapReduce,因为聚合管道通常具有更好的性能。

 川公网安备51010802032098
川公网安备51010802032098