从 Java5 开始,ConcurrentHashMap 已经变成了并发编程的主力军。当然,ConcurrentHashMap 是线程安全的 —— 多个线程不需要对内部结构造成破坏,就可以添加或删除元素。而且它的性能也很不错,允许多个线程并发更新哈希表的不同部分,而不会互相阻塞。
注意,哈希映射会将拥有相同哈希码的所有数据项保存在同一个“块”中。如果应用程序使用了糟糕的哈希函数,导致所有数据项都被保存在了很小一组“块”中,这将严重影响哈希映射的效率。即使是通常认为合理的哈希函数,例如 String 类的 hashCode() 方法,也可能会存在问题。例如,攻击者可以通过构造一组大量的哈希码都一样的字符串来拉低应用程序的速度。在 Java8 中,ConcurrentHashMap 用树型结构来组织“块”,而不再用列表的结构,这样当“键”类实现了 Comparable 接口时,可以保证性能为 αlog(n)。
理解 αlog(n):
αlog(n) 是一个数学表达式。
log(n) 通常指的是以某个特定底数(常见的底数为 10 或自然常数 e )的对数。例如,如果是以 10 为底的对数,log(100) 就等于 2,因为 10^2 = 100 ;如果是以 e 为底的对数(通常记作 ln(n) ),ln(e) 就等于 1 。
而 α 是一个常数系数。
αlog(n) 整体表示对数函数 log(n) 乘以常数 α 。
例如,如果 α = 2 ,n = 100 且是以 10 为底的对数,那么 αlog(n) = 2×log(100) = 2×2 = 4 。
在算法分析中,αlog(n) 这样的表达式常常用于描述算法的时间复杂度或空间复杂度。比如,如果某个算法的复杂度为 O(αlog(n)) ,意味着随着输入规模 n 的增大,算法的运行时间或所需空间与 αlog(n) 成正比,增长速度相对较慢,属于较为高效的算法类型。例如:
log(100)=2 假如输入数据 100 个,耗时 2 秒。
log(1000)=3 假如输入数据 1000 个,耗时 3 秒,增长了 990 个数据,而时间才增长 1 秒。
mappingCount 方法
该返回映射的数量。如果你在哈希表中映射了大量的数据,应使用此方法而不是 size()(size 方法返回类型为 int),因为 ConcurrentHashMap 包含的映射数可能多于可以用 int 表示的映射数。注意,该方法返回值只是一个估计值;如果有并发插入或删除,实际数目可能会有所不同。
方法定义如下:
public long mappingCount()
例如,我们往 ConcurrentHashMap 中映射 10000000 个元素:
package com.hxstrive.jdk8.concurrent.concurrent_hashmap;
import java.util.concurrent.ConcurrentHashMap;
/**
* ConcurrentHashMap 类
* @author hxstrive.com
*/
public class ConcurrentHashMapDemo {
public static void main(String[] args) {
ConcurrentHashMap<Long,String> map = new ConcurrentHashMap<>();
for(long i = 0; i < 10000000; i++) {
map.put(i, "value" + i);
}
System.out.println("count=" + map.mappingCount());
// count=10000000
}
}java8 广告位
更新值
JDK8 之前的 ConcurrentHashMap 只有少量用于原子更新的方法,这也带来了一些糟糕的编程方式。例如,多个线程对同一个 KEY 进行递增操作。如下:
package com.hxstrive.jdk8.concurrent.concurrent_hashmap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* ConcurrentHashMap 类
* @author hxstrive.com
*/
public class ConcurrentHashMapDemo1 {
private static final Map<String,Long> MAP = new ConcurrentHashMap<>();
static class MyTask implements Runnable{
@Override
public void run() {
// 线程不安全
Long oldVal = MAP.get("key");
// 其他线程可能已经将 key 键对应的值修改
oldVal = oldVal == null ? 1 : oldVal + 1;
MAP.put("key", oldVal);
}
}
public static void main(String[] args) {
// 创建线程池
final ExecutorService executor = Executors.newFixedThreadPool(2);
// 提交任务
for (int i = 0; i < 5; i++) {
executor.submit(new MyTask());
}
executor.shutdown();
while(!executor.isTerminated()){
// 等待线程池中的所有线程执行完毕
}
System.out.println(MAP.get("key"));
}
}另一个线程可能同时在更新相同的计数。当然,我们可以粗暴的使用 synchronized 关键字,创建一个同步块,将递增的代码放进去(但是,这会影响性能,不建议这么做),如下:
@Override
public void run() {
// 同步处理
synchronized (MAP) {
Long oldVal = MAP.get("key");
oldVal = oldVal == null ? 1 : oldVal + 1;
MAP.put("key", oldVal);
}
}到这里,可能有读者会问,ConcurrentHashMap 不是线程安全的吗?为什么还会出现上面线程不安全的现象。这是出于两种完全不同的考虑。如果多个线程修改一个普通的 HashMap,可能会破坏 HashMap 内部的结构,其中一些链接可能会丢失,或者形成了回路,从而导致数据结构不可用。在 ConcurrentHashMap 中,这永远不可能发生。上面的示例中,用来 get 和 put 的代码永远不会破坏数据结构。但是,由于操作的顺序不是原子的,因此结果也无法预测。
当然,除了使用 synchronized 关键字,我们还可以使用 Lock 来实现。下面将介绍另一种补救措施:使用 replace 操作,将一个已知的旧值替换为一个新值:
@Override
public void run() {
Long oldVal, newVal;
do {
// 初始化 key 的值,如果 key 不存在,则设置为 0L
MAP.putIfAbsent("key", 0L);
// 获取 key 的值
oldVal = MAP.get("key");
newVal = oldVal + 1;
// replace 操作会对比 oldVal 是否和 key 当前值一致
// 如果一致,则进行替换;否则,不替换,返回 false;
} while(!MAP.replace("key", oldVal, newVal));
}此外,你还可以使用 ConcurrentHashMap<String, AtomicLong> 或者在 Java8 中使用 ConcurrentHashMap<String, LongAdder> 来实现。例如:
@Override
public void run() {
// 如果不存在 key,则设置新的 AtomicLong
MAP.putIfAbsent("key", new AtomicLong(0));
MAP.get("key").incrementAndGet();
}第一条语句确保了存在一个 LongAdder 对象,以便我们用于原子自增。
compute 方法
compute 方法是 ConcurrentHashMap 中的一个非常有用的方法,它允许你以原子方式更新键的值,并且可以根据键的当前值来计算新的值。
ConcurrentHashMap 提供了多个 compute 方法,如下:
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
如果指定的键尚未与值关联(或映射为 null),则尝试使用给定的映射函数计算其值,并在计算成功时输入此映射。即 key 不存在或为 null,才执行 mappingFunction 函数。例如:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
// 如果 “key” 不存在,则添加 “key”,并映射到 “hello value”
map.computeIfAbsent("key", new Function<String, String>() {
@Override
public String apply(String s) {
// key 不存在才调用该方法
System.out.println("apply() s=" + s); // apply() s=key
return "hello value";
}
});
System.out.println(map.get("key")); // hello value
// 如果键存在
map.put("key2", "value2");
map.computeIfAbsent("key2", k -> "hello value2");
System.out.println(map.get("key2")); // value2computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
如果指定的键的值存在且非空,则尝试使用给定的重映射函数计算其新值。即 key 存在且不为 null,才执行 remappingFunction 函数。例如:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
// 如果 “key” 存在,则将 “key” 的值转换为大写
map.put("key", "value1");
map.computeIfPresent("key", new BiFunction<String,String,String>(){
@Override
public String apply(String k, String v) {
return v.toUpperCase();
}
});
System.out.println(map.get("key")); // VALUE1
// 如果不存在
map.computeIfPresent("key2", (k,v) -> v.toUpperCase());
System.out.println(map.get("key2")); // nullcompute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
尝试计算指定键及其当前映射值的映射(或重新映射),即键是否存在,都会调用 remappingFunction 函数,计算新的值。例如:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
// 如果 “key” 存在,则将 “key” 的值转换为大写
map.put("key", "value1");
map.compute("key", new BiFunction<String,String,String>(){
@Override
public String apply(String k, String v) {
return Objects.isNull(v) ? null : v.toUpperCase();
}
});
System.out.println(map.get("key")); // VALUE1
// 如果不存在
map.compute("key2", (k,v) -> Objects.isNull(v) ? null : v.toUpperCase());
System.out.println(map.get("key2")); // null注意:
(1)ConcurrentHashMap 不允许含有 null 值,ConcurrentHashMap 中的许多方法用 null 值来表示映射中不含有指定的键。
(2)如果传递给 compute 方法的函数返回 null, 那么已有的数据项会从映射中删除掉。
merge 方法
merge 方法是另一个非常有用的原子更新方法,它允许你根据键的当前值来合并新的值。如果键不存在于映射中,那么给定的值将简单地与该键关联;如果键已存在,那么会使用提供的合并函数将当前值与给定值合并。
merge 方法的签名如下:
V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
参数说明:
示例:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
// 如果 "one" 不存在,则将其与 World 字符串关联
// 如果 "one" 存在,则将其值与给定的新值相连接
map.merge("one", "Hello", new BiFunction<String,String,String>(){
@Override
public String apply(String oldValue, String newValue) {
return oldValue + " " + newValue;
}
});
System.out.println(map.get("one")); //Hello
// 现在,再次使用 merge 方法与 "one" 关联的值相加
map.merge("one", "World", new BiFunction<String,String,String>(){
@Override
public String apply(String oldValue, String newValue) {
return oldValue + " " + newValue;
}
});
System.out.println(map.get("one")); //Hello World注意:
(1)如果传递给 merge 方法的函数返回 null, 那么已有的数据项会从映射中删除掉。
(2)当你使用 compute 或者 merge 方法时,请牢记你所提供的函数不应该进行大量的工作。当该函数运行时,其他一些更新映射的操作可能会被阻塞。当然,该函数也不应该更新映射的其他部分。
java8 广告位
批量数据操作
Java8 为 ConcurrentHashMap 还提供了数据批量操作,即使在其他线程同时操作 Map 时也可以安全地执行。数据批量操作会遍历 Map 并对匹配的元素进行操作。在数据批量操作过程中,不需要冻结 Map 的一个快照。除非你恰好知道在这段时间内 Map 没有被修改,否则你应该将结果看作是 Map 状态的一个近似值。
Map 数据批量操作有三类:
search 操作
search 操作会对每个键和(或)值应用一个函数,直到该函数返回一个非null的结果。然后search会终止并返回该函数的结果。
<U> U search(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> searchFunction)
该方法在每个(key、value)上应用给定的 searchFunction 函数后,返回一个非空结果,如果没有,则返回空结果。
参数说明:
parallelismThreshold 并行执行此操作所需的(估计)元素数量,如:10000 当元素达到该量级就会使用并发搜索。
searchFunction 一个BiFunction函数式接口类型的参数。BiFunction接受两个参数并返回一个结果。在这里,第一个参数的类型是键K的父类型(? super K),第二个参数的类型是值V的父类型(? super V),返回值的类型是U的子类型(? extends U)。这个函数定义了在每个元素上应用的搜索逻辑和规则。
示例:
(1)下面示例向 Map 中添加了三个元素(k1、k2、k3),然后使用 search 方法搜索名为 k2 的元素,并计算该元素对应值的长度;否则,返回 null。如下:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
Long result = map.search(4, new BiFunction<String, String, Long>() {
@Override
public Long apply(String k, String v) {
System.out.println(Thread.currentThread().getName() + " key=" + k + " value=" + v);
return "k2".equals(k) ? (long)v.length() : null;
}
});
System.out.println("result = " + result);
//结果:
//main key=k1 value=value1
//main key=k2 value=value2
//result = 6通过上面输出可知,当 search 返回非 null 时,search 方法将结束查找。如上例的 k3 就没有被遍历,因为在 k2 已经返回了非空元素。还有,根据返回的信息,执行操作的均是 main 线程。如果我们在搜索函数直接返回 null,那么将遍历 Map 全部元素,例如:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
Long result = map.search(4, new BiFunction<String, String, Long>() {
@Override
public Long apply(String k, String v) {
System.out.println(Thread.currentThread().getName() + " key=" + k + " value=" + v);
return null;
}
});
System.out.println("result = " + result);
//结果:
//main key=k1 value=value1
//main key=k2 value=value2
//main key=k3 value=value3
//result = null如果我们将 serach 的第一个参数设置为小于 Map 元素个数的值,这里设置为 2,会有什么效果,如下:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
Long result = map.search(2, new BiFunction<String, String, Long>() {
@Override
public Long apply(String k, String v) {
System.out.println(Thread.currentThread().getName() + " key=" + k + " value=" + v);
return null;
}
});
System.out.println("result = " + result);
//结果:
//main key=k1 value=value1
//main key=k2 value=value2
//ForkJoinPool.commonPool-worker-1 key=k3 value=value3
//result = null从上例输出可知,此时的 search 方法使用了并发的方式去搜索(这 ForkJoinPool.commonPool-worker-1 使用了 JDK7 添加的 Fork-Join 技术)。
上面均是通过匿名函数的方式来实现,仅仅是为了方便理解,下面给一个 Lambda 表达式实现的示例:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
Long result = map.search(2, (k, v) -> "k2".equals(k) ? (long)v.length() : null);
System.out.println("result = " + result); // result = 2<U> U searchEntries(long parallelismThreshold, Function<Map.Entry<K,V>,? extends U> searchFunction)
该方法在每个条目上应用给定的 searchFunction 函数后,返回一个非 null 结果,如果没有,则返回 null。参数和 search 类似,不再赘述,示例:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
// 搜索 k2 元素,然后返回该元素 key + value 的字符串长度
Long result = map.searchEntries(2, new Function<Map.Entry<String, String>, Long>() {
@Override
public Long apply(Map.Entry<String, String> entry) {
return "k2".equals(entry.getKey()) ?
(long)(entry.getKey().length() + entry.getValue().length()) : null;
}
});
System.out.println("result = " + result); //result = 8<U> U searchKeys(long parallelismThreshold, Function<? super K,? extends U> searchFunction)
该方法在每个键上应用给定的 searchFunction 函数后,返回一个非 null 结果,如果没有,则返回 null。参数和 search 类似,不再赘述,示例:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
// 搜索 k2 元素,然后返回该元素 key 的长度
Long result = map.searchKeys(2, new Function<String, Long>() {
@Override
public Long apply(String k) {
return "k2".equals(k) ? (long)k.length() : null;
}
});
System.out.println("result = " + result); //result = 2
// Lambda 表达式实现
result = map.searchKeys(2, k -> "k2".equals(k) ? (long)k.length() : null);
System.out.println("result = " + result); //result = 2<U> U searchValues(long parallelismThreshold, Function<? super V,? extends U> searchFunction)
该方法在每个值上应用给定的 searchFunction 函数后,返回一个非空结果,如果没有,则返回 null。参数和 search 类似,不再赘述,示例:
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("k1", "value1");
map.put("k2", "value2");
map.put("k3", "value3");
// 搜索 k2 元素,然后返回该元素 key 的长度
Long result = map.searchValues(2, new Function<String, Long>() {
@Override
public Long apply(String v) {
return "value2".equals(v) ? (long)v.length() : null;
}
});
System.out.println("result = " + result); //result = 6
// Lambda 表达式
result = map.searchValues(2, v -> "value2".equals(v) ? (long)v.length() : null);
System.out.println("result = " + result); //result = 6java8 广告位
reduce 操作
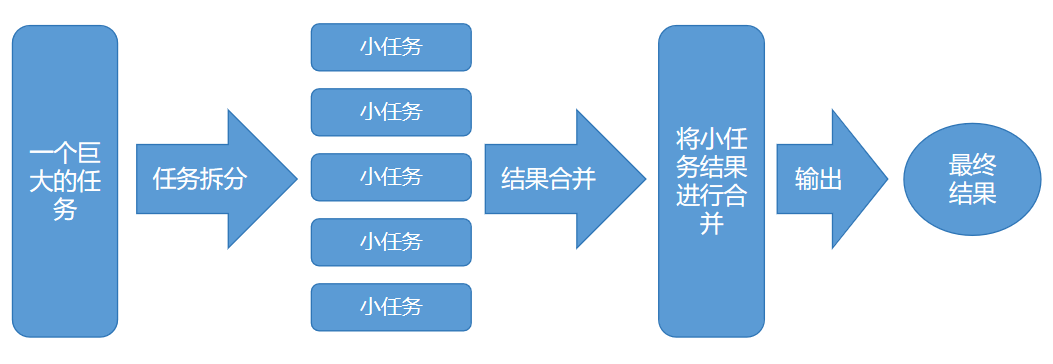
在了解 reduce 操作之前,我们先了解一下 MapReduce 思想。MapReduce 是一种分布式计算模型和编程模型,用于大规模数据集的并行处理。它的核心思想是将复杂的计算任务分解为两个主要阶段:Map(映射)阶段和 Reduce(归约)阶段。如下图:
reduce 操作会通过提供的累积函数,将所有的键和 (或) 值组合起来。方法定义如下:
<U> U reduce(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
该方法的作用是对 ConcurrentHashMap 中的键值对元素进行转换(transformer)和归并(reducer)操作,以生成一个聚合结果。
参数说明:
parallelismThreshold:一个 long 类型的参数,用于确定并行执行的阈值。如果 ConcurrentHashMap 的大小小于此阈值,操作可能会以顺序方式执行;如果大于此阈值,可能会以并行方式执行操作。
BiFunction<? super K,? super V,? extends U> transformer:这是一个函数式接口,用于将 ConcurrentHashMap 中的键值对转换为指定类型 U 的元素。它接受键值对作为参数,并返回转换后的 U 类型的结果。
BiFunction<? super U,? super U,? extends U> reducer:用于归并由 transformer 转换后的结果。它接受两个 U 类型的参数,并返回归并后的 U 类型的结果。
示例:创建一个 Map,该 Map 中存在5个元素,它们值分别为 1...5,使用 reduce 的转换函数先将每个元素的值乘以100,然后将转换后的元素相加,如下:
ConcurrentHashMap<String,Long> map = new ConcurrentHashMap<>();
map.put("k1", 1L); //100
map.put("k2", 2L); //200
map.put("k3", 3L); //300
map.put("k4", 4L); //400
map.put("k5", 5L); //500
Long result = map.reduce(5, new BiFunction<String, Long, Long>() {
@Override
public Long apply(String k, Long v) {
// 数据转换,将每个键值对的值乘以100
return v * 100;
}
}, new BiFunction<Long, Long, Long>() {
@Override
public Long apply(Long s1, Long s2) {
// 将两个结果相加
return s1 + s2;
}
});
System.out.println("result = " + result); //result = 1500
// Lambda 表达式
result = map.reduce(5, (k, v) -> v * 100, (s1, s2) -> s1 + s2);
System.out.println("result = " + result); //result = 1500<U> U reduceEntries(long parallelismThreshold, Function<Map.Entry<K,V>,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
该方法使用 reducer 函数合并由 transformer 函数转换的每一个 Map 值作为结果。如果没有,则返回 null。示例:
ConcurrentHashMap<String,Long> map = new ConcurrentHashMap<>();
map.put("k1", 1L); //100
map.put("k2", 2L); //200
map.put("k3", 3L); //300
map.put("k4", 4L); //400
map.put("k5", 5L); //500
Long result = map.reduceEntries(5, new Function<Map.Entry<String, Long>, Long>() {
@Override
public Long apply(Map.Entry<String, Long> entry) {
return entry.getValue() * 100;
}
}, new BiFunction<Long, Long, Long>() {
@Override
public Long apply(Long s1, Long s2) {
return s1 + s2;
}
});
System.out.println("result = " + result); //result = 1500
// Lambda 表达式
result = map.reduceEntries(5, (entry) -> entry.getValue() * 100, (s1, s2) -> s1 + s2);
System.out.println("result = " + result); //result = 1500<U> U reduceKeys(long parallelismThreshold, Function<? super K,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
该方法使用 reducer 函数合并由 transformer 函数转换的每一个 Map 的 Key 值作为结果。如果没有,则返回 null。示例:
ConcurrentHashMap<String,Long> map = new ConcurrentHashMap<>();
map.put("k1", 1L); //100
map.put("k2", 2L); //200
map.put("k3", 3L); //300
map.put("k4", 4L); //400
map.put("k5", 5L); //500
String result = map.reduceKeys(5, new Function<String, String>() {
@Override
public String apply(String s) {
return "key=" + s.toUpperCase();
}
}, new BiFunction<String, String, String>() {
@Override
public String apply(String s1, String s2) {
return s1 + "," + s2;
}
});
System.out.println("result = " + result);
//result = key=K1,key=K2,key=K3,key=K4,key=K5
// Lambda 表达式
result = map.reduceKeys(5,(k) -> "key=" + k.toUpperCase(), (s1, s2) -> s1 + "," + s2);
System.out.println("result = " + result);
//result = key=K1,key=K2,key=K3,key=K4,key=K5<U> U reduceValues(long parallelismThreshold, Function<? super V,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
该方法使用 reducer 函数合并由 transformer 函数转换的每一个 Map 的 Value 值作为结果。如果没有,则返回 null。示例:
ConcurrentHashMap<String,Long> map = new ConcurrentHashMap<>();
map.put("k1", 1L); //100
map.put("k2", 2L); //200
map.put("k3", 3L); //300
map.put("k4", 4L); //400
map.put("k5", 5L); //500
Long result = map.reduceValues(5, new Function<Long, Long>() {
@Override
public Long apply(Long v) {
return v * 100;
}
}, new BiFunction<Long, Long, Long>() {
@Override
public Long apply(Long v1, Long v2) {
return v1 + v2;
}
});
System.out.println("result = " + result); //result = 1500
// Lambda 表达式
result = map.reduceValues(5, v -> v * 100, (v1, v2) -> v1 + v2);
System.out.println("result = " + result); //result = 1500java8 广告位
Set 视图(KeySetView)
来做一个假设,假设你希望得到一个大的、线程安全的 Set (而不是 Map)。但是 Java8 中没有提供 ConcurrentHashSet 这样的类,并且你不打算自己来写一个。当然,你可以用虚假值构造一个 ConcurrentHashMap,但是接下来你只能获得一个映射,而不是 Set,也就无法应用 Set 接口中的操作。
ConcurrentHashMap 的静态方法 newKeyset() 会返回一个 Set<K> 对象,它实际上就是对 ConcurrentHashMap<K,Boolean> 对象的封装(所有映射的值都是 Boolean.TRUE, 但是实际上你并不关心这些值是什么,因为你将它作为一个 Set 使用)。例如:
ConcurrentHashMap.KeySetView<String,Boolean> set = ConcurrentHashMap.newKeySet();
set.add("one");
set.add("two");
set.add("one");
set.add("three");
set.add("four");
// 输出集合内容
set.forEach(System.out::println);
//four
//one
//two
//three
// 获取集合大小
System.out.println("size = " + set.size()); // size = 4当然,如果你已经有了一个映射,那么 keyset() 方法会返回所有键的 Set。该 Set 是可变的。如果你删除该 Set 中的元素,那么相应的键 (以及它的值) 也会从映射中删除。但是你无法向这个键 Set 中添加元素,因为无法添加相应的值。于是 Java8 又给 ConcurrentHashMap 添加了另一个 keyset(V mappedValue) 方法,它可以接受一个默认值,以便用于向 Set 中添加元素。例如:
ConcurrentHashMap<String,Long> map = new ConcurrentHashMap<>();
map.put("k1", 1L); //100
map.put("k2", 2L); //200
map.put("k3", 3L); //300
map.put("k4", 4L); //400
map.put("k5", 5L); //500
ConcurrentHashMap.KeySetView<String,Long> set = map.keySet();
// 删除一个元素
set.remove("k3");
// 添加一个元素,抛出 java.lang.UnsupportedOperationException 错误
//set.add("k6");
System.out.println("size = " + set.size()); //size = 5
System.out.println(Arrays.toString(set.toArray())); //[k1, k2, k3, k4, k5]
// 另一个 keySet
ConcurrentHashMap.KeySetView<String,Long> set2 = map.keySet(0L);
set2.add("k6"); // 添加元素,值为 keySet() 方法设置的值 0l
System.out.println(Arrays.toString(set2.toArray())); //[k1, k2, k3, k4, k5, k6]
// 打印 Map 内容
map.forEach((k,v)-> System.out.println(k + " : " + v));
//k1 : 1
//k2 : 2
//k4 : 4
//k5 : 5
//k6 : 0



 川公网安备51010802032098
川公网安备51010802032098