在 JDK7 中,Fork/Join 框架是一种用于并行执行任务的高效框架,主要用于实现分治算法,能够充分利用多核处理器的优势,提高程序的性能。
在了解 Fork/Join 之前,我想先解释一下 Fork/Join 的一般工作原理。Fork/Join 框架的主要概念有:
Fork(任务分割)
Fork 指将一个大的任务分解成多个小的子任务,每个子任务都可以独立地并行执行。这个过程类似于分治算法中的分割步骤。例如,要计算一个大型数组的总和,可以将数组分成若干个较小的子数组,每个子数组的求和任务可以并行执行。如下图所示:
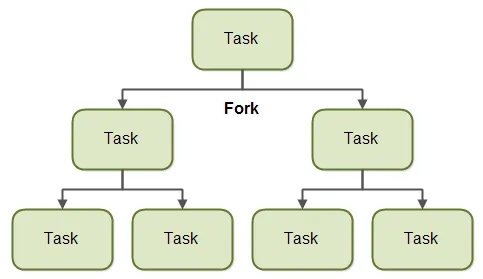
上图中,顶部的一个任务,到底部将分割为四个任务。通过将自身拆分成子任务,每个子任务可以由不同的 CPU 或同一 CPU 上的不同线程并行执行。
⚠️注意:
(1)只有当任务分配给它的工作量足够大时,任务才会被拆分成子任务。将任务拆分成子任务会产生一定的开销,因此对于少量工作而言,这种开销可能会大于并行执行子任务所带来的速度提升。
(2)何时将任务 Fork 为子任务才有意义的限制也称为阈值。阈值由每个任务自行决定。这在很大程度上取决于所做工作的类型。
Fork 示例
假如我们需要对 100000 个数据进行处理,我们利用多次 Fork,将任务拆分成大小为 3215(这就是阈值)的子任务,如下图:
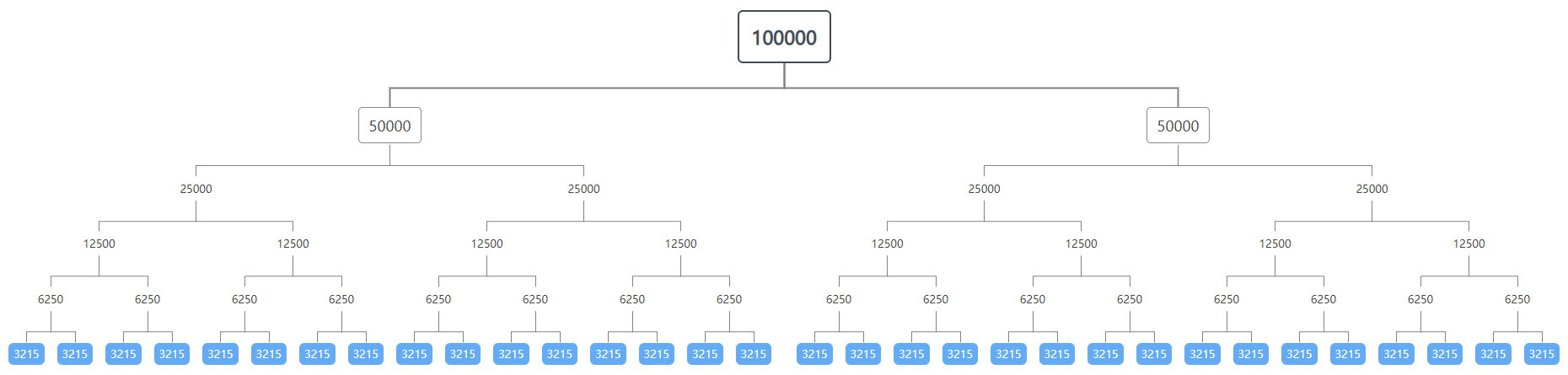
如上图,我们得到了 32 个具体处理的子任务,此时就可以利用多线程来处理这些子任务,提升数据处理效率。
javaN 广告位
Join(结果合并)
当 Fork 出来的所有子任务完成后,将它们的结果合并起来得到最终的结果,就称为 Join(结果合并)。这类似于分治算法中的合并步骤。
当一个任务将自己分割成多个子任务时,该任务会等待子任务执行完毕。子任务执行完毕后,任务可将所有结果连接(合并)为一个结果。如下图所示:
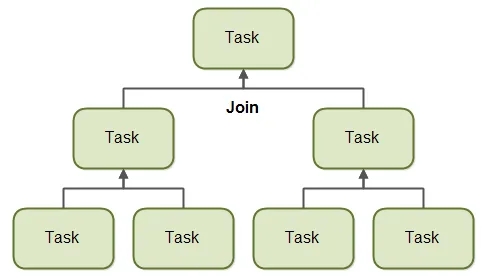
当然,并非所有类型的任务都会返回结果。如果任务不返回结果,那么任务只是等待其子任务完成。此时不会进行结果合并。
Join 示例
假如我们需要对 100000 个数据进行处理,我们利用多次 Fork,将任务拆分成大小为 3215(这就是阈值)的子任务,然后通过 Join 合并这些任务的结果。如下图:
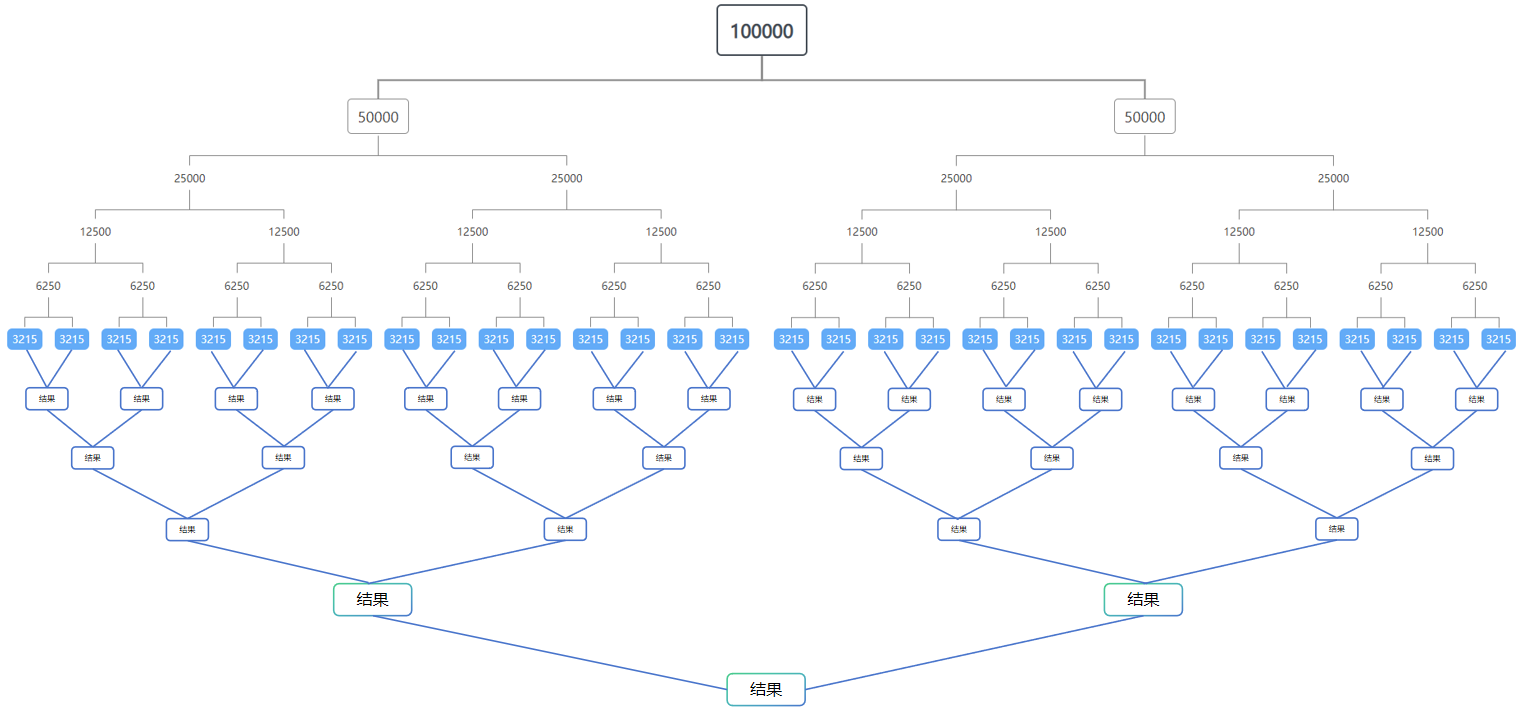
上图和 Fork 步骤恰好相反,将多个任务的结果逐步合并,直到只有一个结果。

 川公网安备51010802032098
川公网安备51010802032098