火焰图可以让剖析数据可视化。使用这种可视化方式,剖面图可以用火焰图、表格或两者来表示,如下图:
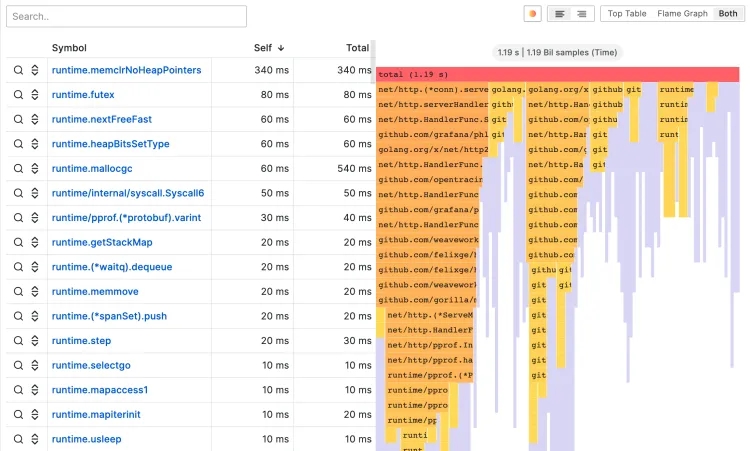
一个示例
该实例使用 mysql 作为 grafana 的数据源,假如存在如下数据表:
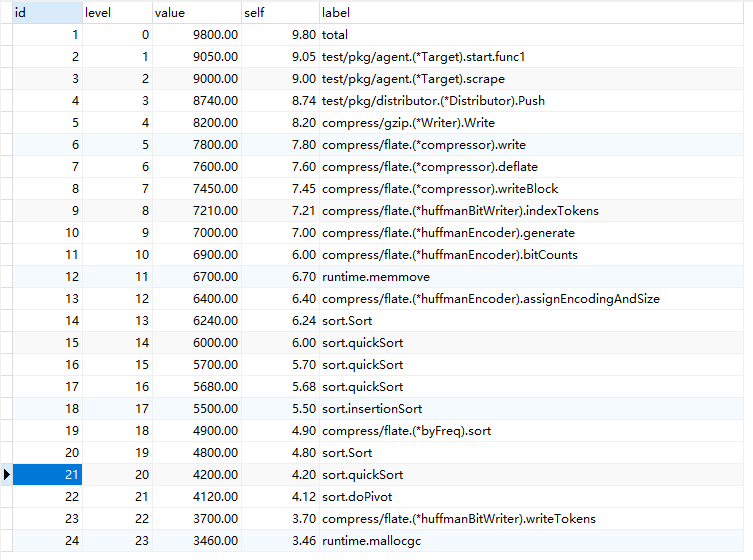
该数据表格的 SQL 语句如下:
CREATE TABLE `flame_graph_data` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`level` int(10) DEFAULT NULL,
`value` DECIMAL(10,2) DEFAULT NULL,
`self` DECIMAL(10,2) DEFAULT NULL,
`label` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
表对应的数据 SQL 语句如下:
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (1, 0, 9800.00, 9.80, 'total');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (2, 1, 9050.00, 9.05, 'test/pkg/agent.(*Target).start.func1');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (3, 2, 9000.00, 9.00, 'test/pkg/agent.(*Target).scrape');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (4, 3, 8740.00, 8.74, 'test/pkg/distributor.(*Distributor).Push');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (5, 4, 8200.00, 8.20, 'compress/gzip.(*Writer).Write');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (6, 5, 7800.00, 7.80, 'compress/flate.(*compressor).write');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (7, 6, 7600.00, 7.60, 'compress/flate.(*compressor).deflate');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (8, 7, 7450.00, 7.45, 'compress/flate.(*compressor).writeBlock');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (9, 8, 7210.00, 7.21, 'compress/flate.(*huffmanBitWriter).indexTokens');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (10, 9, 7000.00, 7.00, 'compress/flate.(*huffmanEncoder).generate');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (11, 10, 6900.00, 6.00, 'compress/flate.(*huffmanEncoder).bitCounts');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (12, 11, 6700.00, 6.70, 'runtime.memmove');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (13, 12, 6400.00, 6.40, 'compress/flate.(*huffmanEncoder).assignEncodingAndSize');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (14, 13, 6240.00, 6.24, 'sort.Sort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (15, 14, 6000.00, 6.00, 'sort.quickSort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (16, 15, 5700.00, 5.70, 'sort.quickSort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (17, 16, 5680.00, 5.68, 'sort.quickSort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (18, 17, 5500.00, 5.50, 'sort.insertionSort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (19, 18, 4900.00, 4.90, 'compress/flate.(*byFreq).sort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (20, 19, 4800.00, 4.80, 'sort.Sort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (21, 20, 4200.00, 4.20, 'sort.quickSort');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (22, 21, 4120.00, 4.12, 'sort.doPivot');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (23, 22, 3700.00, 3.70, 'compress/flate.(*huffmanBitWriter).writeTokens');
INSERT INTO `flame_graph_data` (`id`, `level`, `value`, `self`, `label`) VALUES (24, 23, 3460.00, 3.46, 'runtime.mallocgc');
打开 grafana,创建火焰图(Flame graph),使用如下 SQL 语句作为火焰图的数据,SQL 如下:
select `level`, `value`, `self`, `label` from `grafana`.`flame_graph_data`
效果如下图:

Flame graph mode
火焰图利用了剖析数据的层次性。它将数据浓缩成一种格式,让你可以轻松查看哪些代码路径消耗了最多的系统资源,如 CPU 时间、分配对象或内存空间。火焰图中的每个块代表堆栈中的一个函数调用,其宽度代表其值。如下图:

灰色部分是一组代表相对较小数值的函数,出于性能考虑,它们被合并为一个部分。
您可以将鼠标悬停在特定函数上查看工具提示,该提示会显示有关该函数的其他数据,如函数值、占总值的百分比以及使用该函数的样本数。
Drop-down actions
您可以单击某个功能,以显示包含其他操作的下拉菜单:
Focus block
Copy function name
Sandwich view
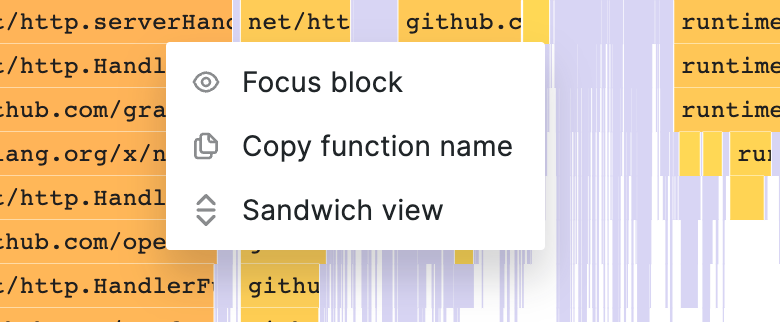
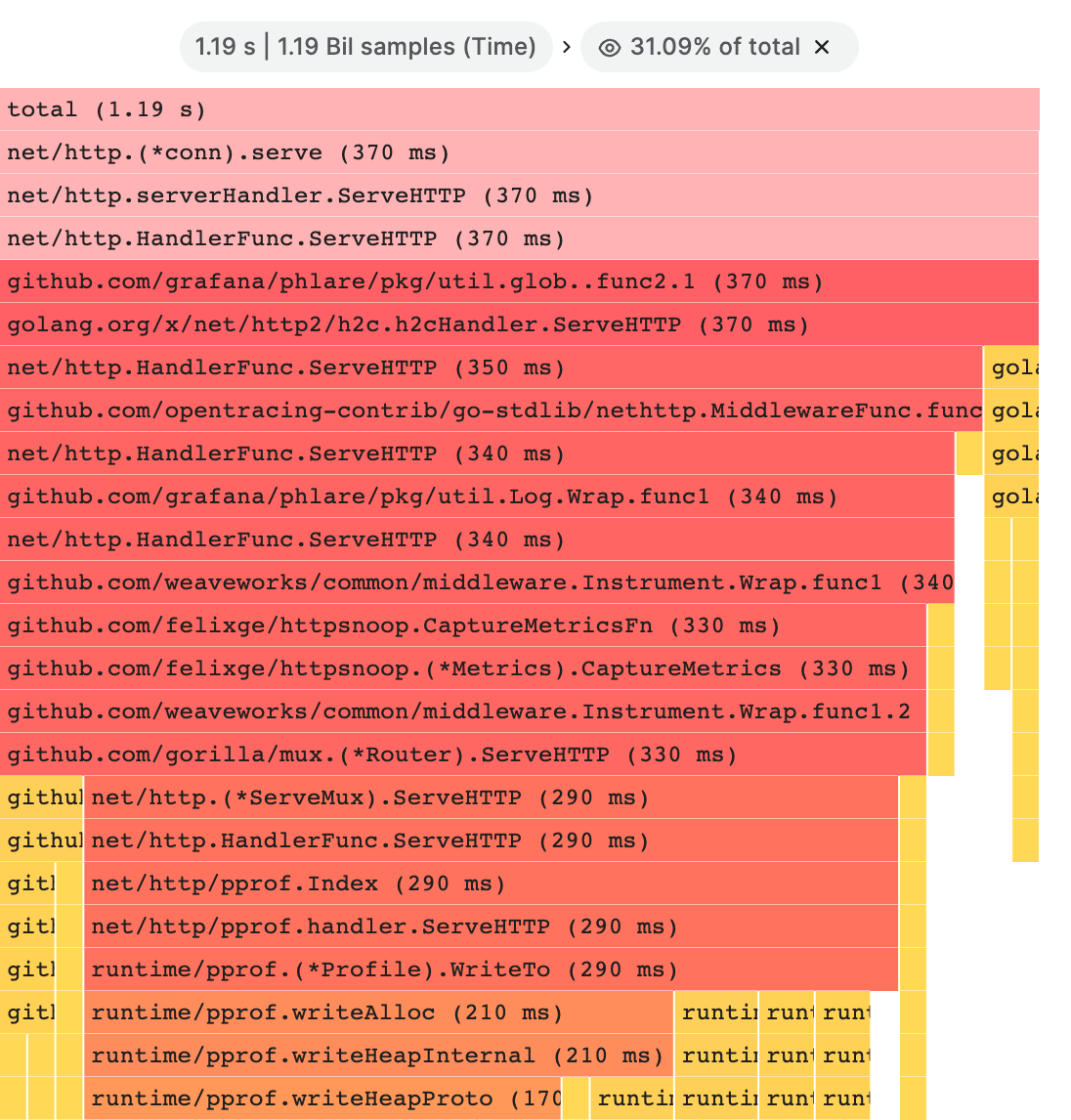
Focus block
单击 "Focus block" 后,该区块或函数将被设置为火焰图形宽度的 100%,其所有子函数都将显示,并根据父函数的宽度更新其宽度。这样可以更方便地深入研究火焰图形的较小部分。如下图:
Copy function name
单击 "Copy function name" 时,块所代表的函数全名将被复制。
Sandwich view
三明治视图可以显示被点击函数的上下文。它在顶部显示函数的所有调用者,在底部显示所有被调用者。这显示了函数的聚合上下文,因此如果函数存在于火焰图中的多个位置,所有上下文都会在三明治视图中显示和聚合。如下图:

Status bar(状态栏)
状态栏显示有关火焰图形和当前应用的修改的元数据,如图形的哪个部分处于焦点或夹层视图中显示的功能。单击状态栏药丸中的 X 可移除该修改。如下图:

Toolbar(工具栏)
Search
您可以使用搜索栏查找具有特定名称的函数。火焰图中与搜索匹配的所有函数都将保持彩色,而其他函数则显示为灰色。如下图:
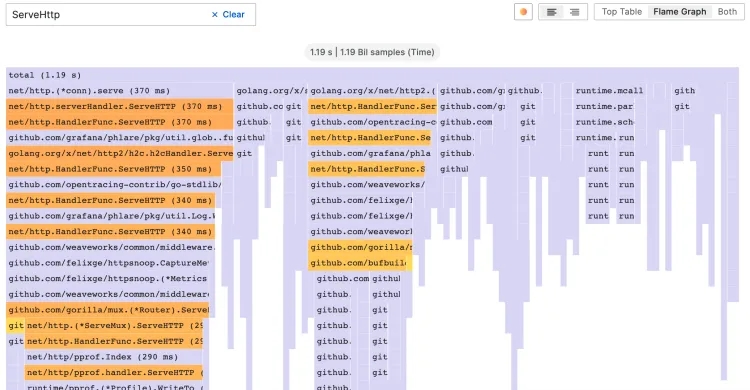
Color schema picker
您可以根据函数的值或软件包名称切换着色函数,以便直观地将同一软件包中的函数联系在一起。如下图:
Text align
将文本向左或向右对齐,以便在功能块中无法显示时,显示功能名称中更重要的部分。
Visualization picker
您可以选择只显示火焰图、只显示表格或同时显示两者。
Top table mode(表格模型)
上表以表格形式显示了配置文件中的功能。表格有三列:符号(Symbol)、自身(Self)和总计(Total)。表格默认按自身时间排序,但也可以通过点击列标题按总时间或符号名称重新排序。如果给定函数在配置文件中出现多处,则每行表示该函数的汇总值。
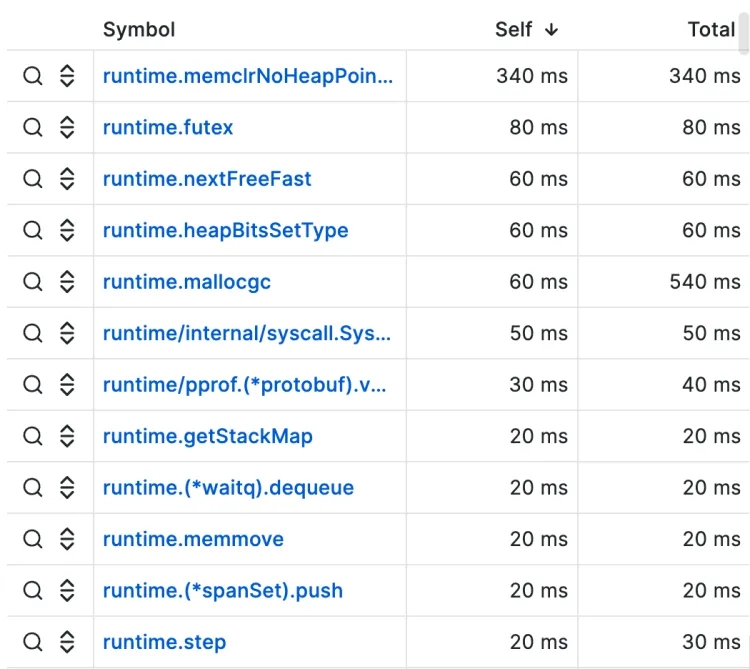
每一行的左侧还有操作按钮。第一个按钮搜索函数名称,第二个按钮显示函数的夹层视图。
Data API(数据API)
为了渲染火焰图,必须使用嵌套模型对数据帧数据进行格式化。
嵌套模型可确保火焰图中的每个项都能以整数值的嵌套级别、元数据及其在数据帧中的顺序进行编码。这意味着项的顺序非常重要,必须正确。排序是对火焰图中项的深度优先遍历,这样就可以重新创建火焰图,而不需要像子数组那样在数据帧中使用变长值。
必填字段:
字段名 | 类型 | 描述 |
level | number | 项目的嵌套级别。换句话说,该项目与火焰图的顶层项目之间有多少个项目。 |
value | number | 项目的绝对值或累计值。这相当于图表中项目的宽度。 |
label | string | 为特定项目显示的标签。 |
self | number | 自身值,通常是该项目的累计值减去其直接子项的累计值之和。 |

 川公网安备51010802032098
川公网安备51010802032098