Map-Reduce 是一种数据处理模式,用于将大量数据浓缩成有用的聚合结果。对于 Map-Reduce 操作,MongoDB 提供 mapReduce 数据库命令。考虑下面的 map-reduce 操作:

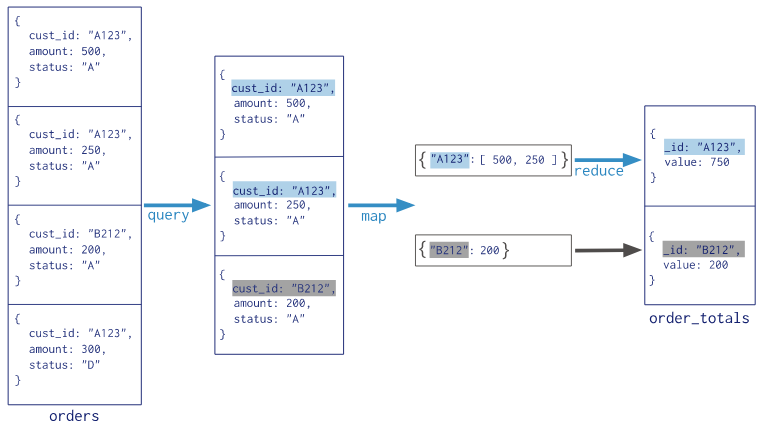
在这个 map-reduce 操作中,mongodb 将映射阶段应用于每个输入文档(即集合中与查询条件匹配的文档)。map 函数发出键值对。对于那些具有多个值的键,MongoDB 应用了 reduce 阶段,该阶段收集并压缩聚合的数据。然后 MongoDB 将结果存储在集合中。可选地,reduce 函数的输出可以通过 finalize 函数进一步浓缩或处理聚合的结果。
MongoDB 中的所有 map-reduce 函数都是 JavaScript,并在 mongod 进程中运行。map-reduce 操作,将单个集合的文档作为输入,在开始 map 阶段之前可以执行任意排序和限制。mapReduce 可以将 map-reduce 操作的结果作为文档返回,也可以将结果写入集合。
注意:对于大多数聚合操作,聚合管道提供更好的性能和更一致的接口。但是,map-reduce操作提供了一些灵活性,这在聚合管道中目前还没有。
mongodb广告位
Map-Reduce JavaScript 函数
在 MongoDB 中,map-reduce 操作使用自定义 JavaScript 函数将值映射或关联到键。如果一个键有多个映射到它的值,则 reduces 操作将键的值减少到单个对象。
自定义 JavaScript 函数的使用为 map-reduce 操作提供了灵活性。例如,在处理文档时,map函数可以创建多个键和值映射,或者不创建映射。map-reduce 操作还可以使用一个定制的 JavaScript 函数对map 和 reduce操作的结果进行最后的修改,比如执行额外的计算。
从4.2.1版开始,MongoDB反对在 map、reduce 和 finalize 函数中使用带有作用域(即BSON类型15)的JavaScript。要确定变量的作用域,请使用作用域参数。
Map-Reduce 结果
在 MongoDB 中,map-reduce 操作可以将结果写入集合或内联返回结果。如果将 map-reduce 输出写入集合,则可以在合并替换、合并或将新结果与先前结果合并的相同输入集合上执行后续的 map-reduce操作。
当以内联方式返回 map-reduce 操作的结果时,结果文档必须在 BSON 文档大小限制之内,目前这个限制是16兆字节。
Map-Reduce 和分片集合
MongoDB 支持对分片集合进行 map-reduce 操作,无论分片集合是作为输入(IN)还是作为输出(OUT)。
但是,从4.2版开始,MongoDB 就不支持使用 map-reduce 选项来创建新的分片集合,也不支持 map-reduce 使用 sharded 选项。若要输出到分片集合,首先需要创建该分片集合。MongoDB4.2 也不赞成替换现有的分片集合。
分片集合作为输入
当使用分片集合作为 map-reduce 操作的输入时,mongos 将自动并行地将 map-reduce 作业分派给每个分片,不需要特殊选项,mongos 将等待所有碎片上的工作完成。
分片集合作为输出
如果 mapReduce 的 out 字段有 sharded 值,MongoDB 使用 _id 字段作为分片键对输出集合进行分片。若要输出到分片集合,请执行以下操作:
如果输出集合不存在,请首先创建分片集合。
从4.2版开始,MongoDB不赞成替换现有的分片集合。
从4.0版开始,如果输出集合已经存在但不是分片集合,则 map-reduce 失败。
对于新的或空的分片集合,MongoDB 使用 map-reduce 操作第一阶段的结果去创建分布在分片之间的初始化块。
mongos 并行地将一个 map-reduce 的后续处理作业分派给每个拥有块的分片。在后期处理期间,每个分片将从其他分片中为自己的块提取结果,运行最后的 reduce/finalize,并在本地将结果写入输出集合。
注意:
mongodb广告位
Map-Reduce 并发性
map-reduce 操作由许多任务组成,包括对输入集合的读取、map 函数的执行、reduce 函数的执行、在处理期间对临时集合的写入以及对输出集合的写入。在操作过程中,map-reduce 获取以下锁:
注意:
后处理期间的最终写锁使结果自动显示。但是,merge 和 reduce 输出操作可能需要几分钟的时间。对于 merge 和 reduce,nonAtomic 标记是可用的,它在写入每个输出文档之间释放锁。从 MongoDB 4.2 开始,显式地设置 nonAtomic:false 是不赞成的。






 川公网安备51010802032098
川公网安备51010802032098