SELECT语句返回用指定的条件在一个数据库中查询的结果,返回的结果被看作记录的集合。语法:SELECT [predicate] { * | table.* | [table.]field1 [AS alias1] [, [table.]field2 [AS alias2] [, ...]]} FROM tableexpression [, ...] [IN externaldatabase] [WHERE... ] [GROUP BY... ] [HAVING... ] [ORDER BY... ] [WITH OWNERACCESS OPTION]
SELECT语句返回用指定的条件在一个数据库中查询的结果,返回的结果被看作记录的集合。SELECT语法如下:
SELECT [predicate] { * | table.* | [table.]field1 [AS alias1] [, [table.]field2 [AS alias2] [, ...]]}
FROM tableexpression [, ...] [IN externaldatabase]
[WHERE criteria]
[GROUP BY fieldlist]
[HAVING ]
[ORDER BY [DESC|ASC]]
[WITH OWNERACCESS OPTION]
说明:
predicate 可选参数,该参数可取值为ALL(缺省值)、DISTINCT、DISTINCTROW 或TOP。
如果该参数为ALL,则返回SQL语句中符合条件的全部记录;
如果为DISTINCT,则省略选择字段中包含重复数据的记录;
如果为DISTINCTROW,则省略基于整个重复记录的数据,而不只是基于重复字段的数据;如果为TOP n(n为一个整数),则返回特定数目的记录,且这些记录将落在由ORDER BY 子句指定的前面或后面的范围中。
* 参数用于指定特定表中的全部字段。
Table 参数用于指定表的名称。
field1,field2 用于指定字段的名称,该字段包含了您要获取的数据。
alias1,alias2 用于指定字段的别名,以代替表中原有的字段名。
FORM 子句用于指定表或查询,该表的查询包含SELECT语句中列举的字段。
tableexpression 参数是用于指定一个或多个表的表达式,并且从这些表中获取数据。
externaldatabase 参数用于指定外部数据库的完整路径,该数据库包含tableexpression中的所有的表。使用 IN 子句一次只能连接一个外部数据库。
WHERE 子句用于指定查询记录的条件,如果省略该子句,则查询将返回表中的所有行。
criteria 参数是一个表达式,用于指定查询的条件。WHERE子句最多可包含40个表达式,当输入的字段名包含空格或标点符号时,要使用括号[]将它括起来。
GROUP BY 将记录与指定字段中的相等值组合成单一记录。如果 SELECT 语句包含 SQL 合计函数,比如 Sum 或 Count,则每一笔记录都会给出一个总计值。
fieldlist 参数用于指定将记录分组的字段名,该参数中的字段名的顺序决定组的层次,它最多可以使用10 个字段。
HAVING 子句在 SELECT 语句中指定,显示哪些已用 GROUP BY 子句分组的记录。在 GROUP BY 组合这些记录后,HAVING 将显示那些经 GROUP BY 子句分组并满足 HAVING 子句中条件的记录。
groupcriteria 参数是一个表达式,用以决定应显示的已分组记录,该子句最多可包含40个表达式。
ORDER BY 子句指定按照递增或递减顺序在指定字段中对查询的结果记录进行排序。
sql广告位
SELECT语句实例:
select最简短写法
SELECT 列名称 FROM 表名称
以及:
SELECT * FROM 表名称
注意:SQL语句对大小写不敏感。SELECT 等效于 select。
创建Test表:
CREATE TABLE test (
n_id int(11) NOT NULL AUTO_INCREMENT,
c_alias varchar(100) DEFAULT NULL,
c_constellation varchar(100) DEFAULT NULL,
c_name varchar(200) DEFAULT 200,
c_sex char(1) DEFAULT 1,
n_age int(11) DEFAULT NULL,
PRIMARY KEY (`n_id`)
)
// 部分数据
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天魁星', '呼保义', '宋江', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天罡星', '玉麒麟', '卢俊义', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天机星', '智多星', '吴用', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天闲星', '入云龙', '公孙胜', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天勇星', '大 刀', '关胜', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天雄星', '豹子头', '林 冲', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天猛星', '霹雳火', '秦 明', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天威星', '双 鞭', '呼延灼', '1', 22);
INSERT INTO test(c_constellation, c_alias, c_name, c_sex, n_age) VALUES('天英星', '小李广', '花 荣', '1', 22);
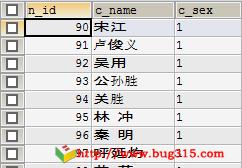
1、查询test表中所有的n_id、c_name和c_sex列的数据
SELECT a.n_id, a.c_name, a.c_sex FROM test a;
结果:
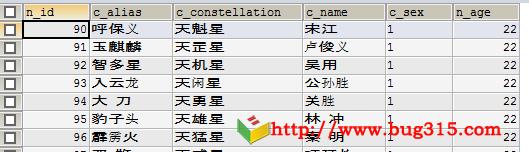
2、在select中使用通配符
SELECT * FROM test;
结果:
3、在select中使用where条件,选择名字中有“明”字的人员信息。
SELECT * FROM test WHERE c_name LIKE '%明%';
结果:

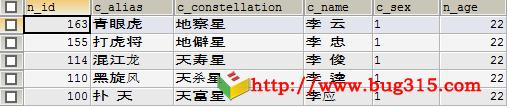
4、在select中使用order by语句进行排序。按照n_id进行降序排序。
SELECT * FROM test WHERE c_name LIKE '%李%' ORDER BY n_id DESC;
结果:
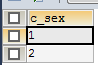
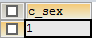
5、在select中使用group by语句对c_sex列进行分组。
SELECT c_sex FROM test GROUP BY c_sex
6、使用select中的having对分组进行过滤。下面过滤掉c_sex!=1的数据行
SELECT c_sex FROM test GROUP BY c_sex HAVING c_sex=1;






 川公网安备51010802032098
川公网安备51010802032098