LLM 模型幻觉(Hallucination)指的是大语言模型生成的看似合理,但实际上不正确、与输入 prompt 无关或相互冲突的内容。
LLM 是一个强大的工具。但它们会产生幻觉,即胡编乱造。减少聊天机器人幻觉的最快、最有效的方法就是使用 Gleen AI。
大型语言模型中的幻觉相当于生成式人工智能领域中的思维漂移。虽然它们看似无害甚至幽默,但也会产生严重的影响。
在本文中,我们将探讨什么是 LLM 幻觉。我们还将讨论它发生的原因,以帮助您解决问题。
什么是 LLM 幻觉?
大型语言模型或 LLM 是一种人工智能(AI)算法,可以识别、解码、预测和生成内容。
虽然该模型能从训练数据中获得一些知识,但它也容易产生 “幻觉”。LLM 中的幻觉是指包含无意义或与事实不符的文本的回复。
例如,模型可能会捏造不存在的事实、出现推理错误、产生数据驱动的偏见,或者在回答中与已知的世界知识不符、与用户提供的源输入不一致、与之前生成的信息相矛盾等。
LLM 幻觉例子
最近 Tidio 的一项调查发现,72% 的用户相信 AI 能够提供真实可靠的信息。此外,75% 的受访者表示,AI 至少误导过一次。因此,请注意以下 LLM 产生幻觉的例子:
源冲突(Source Conflation)
来源混淆是指模型产生事实矛盾。这种 LLM 幻觉问题的出现是因为模型试图将从不同来源提取的细节结合起来。
有时,LLM 甚至会编造来源。
事实错误(Factual Error)
语言模型无法区分真假。因此,LLM 可以生成没有事实根据的内容。
如果使用准确的数据进行训练,带有事实错误的 LLM 幻觉就不那么常见了。
但是,请记住,像 GPT-3.5 和 GPT-4 这样的预训练模型是在整个互联网上训练出来的,而互联网上有很多事实错误。 因此,对 LLM 生成的所有内容进行事实检查仍然是一种好的做法。
无意义信息(Nonsensical Information)
LLM 只是预测句子中下一个最有可能出现的单词。
大多数情况下,它们生成的内容是有意义的。不过,它们也会生成语法正确但毫无意义的文本。更糟糕的是,LLMs 还能做出听起来令人信服且具有权威性的回答,而事实上这些回答根本没有任何事实依据。
一般来说,LLMs 产生幻觉的例子是无害的,甚至是幽默的。然而,在接受 Datanami 采访时,Got It AI 的联合创始人彼得-瑞兰(Peter Relan)说,ChatGPT 有 20% 的时间是在 “胡编乱造”。
什么会导致 LLM 产生幻觉?
一家新创公司的研究发现,ChatGPT 大约有 3% 的时间会产生幻觉。这并不奇怪,尤其是因为深度学习模型会表现出不可预测的行为。
针对 LLM 幻觉问题,利益相关者必须主动实施安全、可靠和可信的人工智能。此外,了解这些情况发生的原因也不无裨益。
那么,是什么导致 LLM 产生幻觉呢?
未经验证的训练数据 —— 大型语言模型本身无法区分事实和虚构。因此,当您向它提供大量不同的训练数据而不对数据来源进行适当验证时,它就会捕捉到与事实不符的数据。
提示语境不充分/不准确 —— 当您使用不充分或不准确的提示时,LLM 的行为可能会不稳定。此外,当你的目标模糊不清时,它可能会生成不正确或不相关的回答。
目标不一致 —— 大多数公共 LLM 都接受过一般自然语言过程的训练。在推断法律、医学和金融等特定领域主题的回答时,这些模型需要额外的帮助。
最重要的是,这只是概率问题 —— LLM 只是预测对话中下一个最可能出现的单词,而不是最准确的单词。LLM 不知道生成的回答是否准确。
AI广告位
LLM 幻觉可以预防吗?
您可能会问,是否可以消除 LLM 的幻觉?
简短的回答是 “不能”。
幻觉自然会出现在 LLM 中,因为它们是这些模型运作的关键部分。不过,你可能会注意到,有些 LLM 比其他 LLM 产生的幻觉更多。
2023 年的一项研究向 LLMs 喂食了 1000 份文件,每次一份。研究人员要求 GPT、Llama、Cohere、Google Palm 和 Mistral 等 LLM 对每份文档进行总结。研究发现,这些 LLM 在 3% 到 27% 的时间内产生了幻觉。如下图:
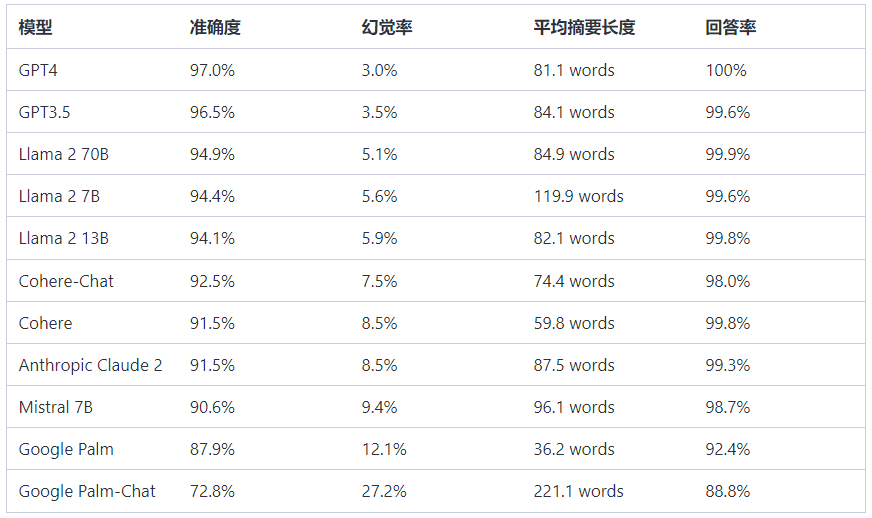
因此,你可以将幻觉视为 LLM 的内置功能。
幻觉是坏事吗?
虽然 LLM 中的幻觉会产生严重影响,但它们并不总是坏事。例如,当你想给模型更多的创作自由时,幻觉就很有用。
由于 LLM 使用的是训练数据,幻觉可以让它们为小说生成独特的场景、人物和故事情节。
另一个 LLM 幻觉可以带来好处的例子是当您在寻找多样性时。
训练数据将为模型提供所需的想法。但是,允许它在一定程度上产生幻觉可以让你探索不同的可能性。
另一方面,在准确性极为重要的使用案例中,LLM 中的幻觉可能是一件坏事。它们会传播虚假信息,放大社会偏见,降低深度学习模型的可信度。
此外,LLM 的幻觉也会给全自动服务带来问题。例如,聊天机器人的幻觉可能会导致糟糕的客户体验。
如何尽量减少 LLM 中的幻觉?
虽然无法避免大型语言模型中出现幻觉,但有一些方法可以将幻觉降至最低。您可以使用以下技巧:
高度描述性提示 —— 通过向模型提供高度描述性提示,为其提供额外的语境。通过给它提供清晰的特征,它可能就不会认为你是在以事实为依据。因此,它就不太可能产生幻觉。
LLM 微调 —— 你可以为 LLM 提供特定领域的训练数据。这样做可以对模型进行微调,使其生成更相关、更准确的反应。
检索增强生成(RAG)—— 该框架的重点是为 LLM 提供最终用户问题和围绕问题的上下文,即知识库中最准确、最相关的信息。 LLM 利用问题和上下文生成更准确、更相关的响应。
在 LLM 层外解决幻觉问题 —— 与其在 LLM 层尽量减少幻觉,您可以部署生成式人工智能解决方案,如 Gleen AI。 Gleen AI 通过仔细选择 LLM 的输入和检测 LLM 输出中的幻觉来解决聊天机器人层的幻觉问题。








 川公网安备51010802032098
川公网安备51010802032098