本文将介绍怎样处理 Exception in thread "main" java.lang.NumberFormatException: For input string: "16329" 错误。
完整代码如下:
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author hxstrive.com
*/
public class Demo20230530153028 {
private static final Map<String,Integer> CACHE = new HashMap<>();
public static void main(String[] args) throws Exception {
new Demo20230530153028();
}
public Demo20230530153028() throws Exception {
System.out.println("Reading file...................");
File file = FileUtils.getFile("C:\Users\Administrator\Desktop\data.txt");
List<String> list = FileUtils.readLines(file, "UTF-8");
System.out.println("Data analysis..................");
for(String row : list) {
int key = Integer.parseInt(row);
if(key > 100 && key < 1000) {
key = (key % 100) * 100;
} else if(key > 1000) {
key = (key % 1000) * 1000;
}
int val = CACHE.getOrDefault(String.valueOf(key), 0);
CACHE.put(row, val + 1);
}
System.out.println("Write to file...................");
List<String> tmpList = new ArrayList<>();
for(Map.Entry<String,Integer> entry : CACHE.entrySet()) {
tmpList.add(entry.getKey() + "," + entry.getValue());
}
FileUtils.writeLines(
FileUtils.getFile("C:\Users\Administrator\Desktop\data-" + System.currentTimeMillis() + ".csv"),
tmpList);
System.out.println("finished.");
}
}
运行上面代码,抛出如下错误信息:
Reading file...................
Data analysis..................
Exception in thread "main" java.lang.NumberFormatException: For input string: "16329"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at com.hxstrive.demo.Demo20230530153028.<init>(Demo20230530153028.java:28)
at com.hxstrive.demo.Demo20230530153028.main(Demo20230530153028.java:18)
java广告位
解决方案
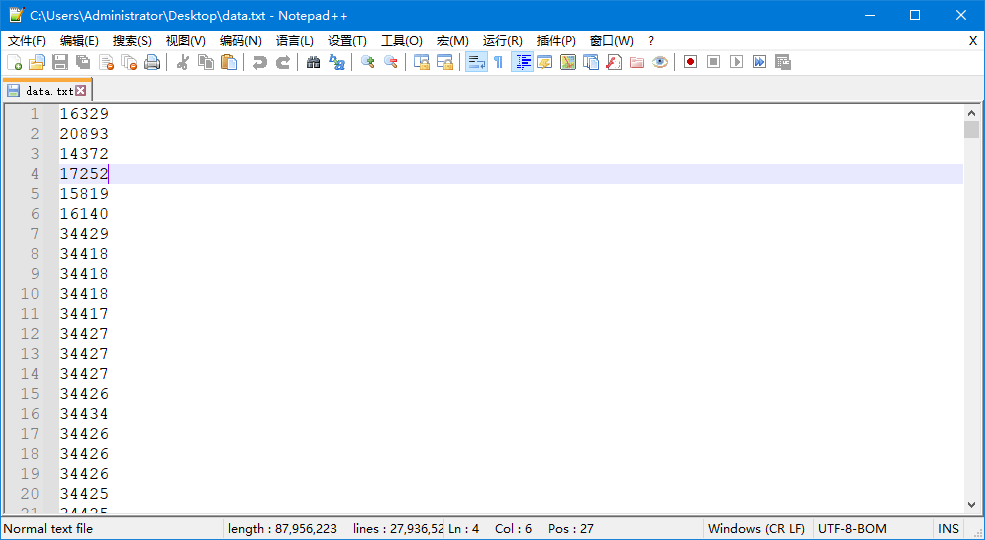
(1)我们有如下数据,每行是一个数字字符串(特别注意,文件的编码为 UTF-8-BOM),如下图:
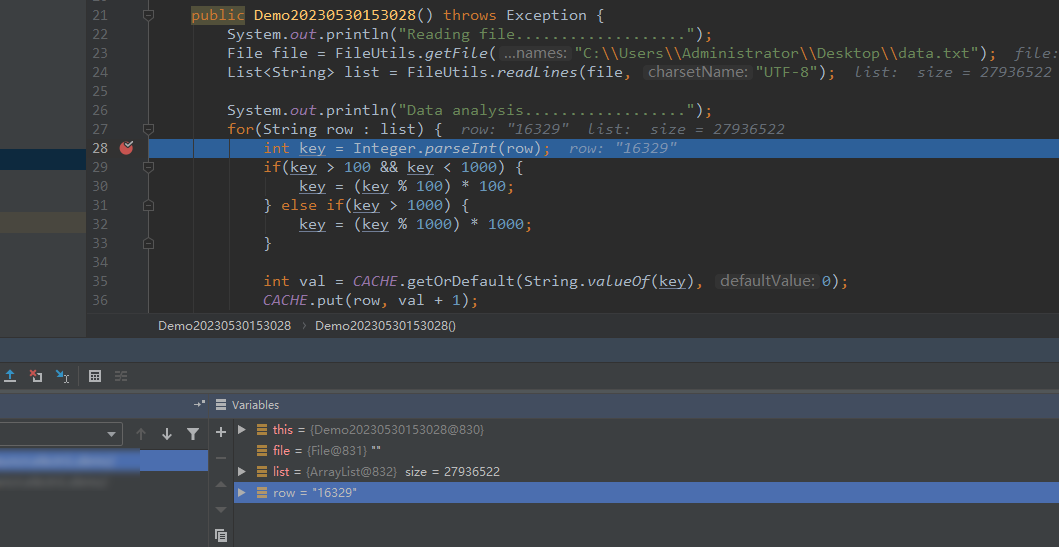
(2)为了解决问题,我们打了一个断点,分析问题,如下图:
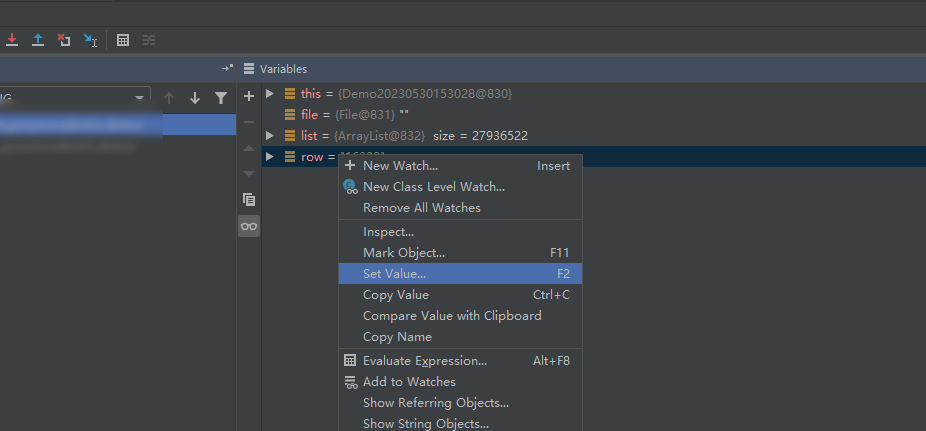
(3)选择 row 变量,然后右键,选择“Set Value...”菜单项去设置 row 变量的值,如下:
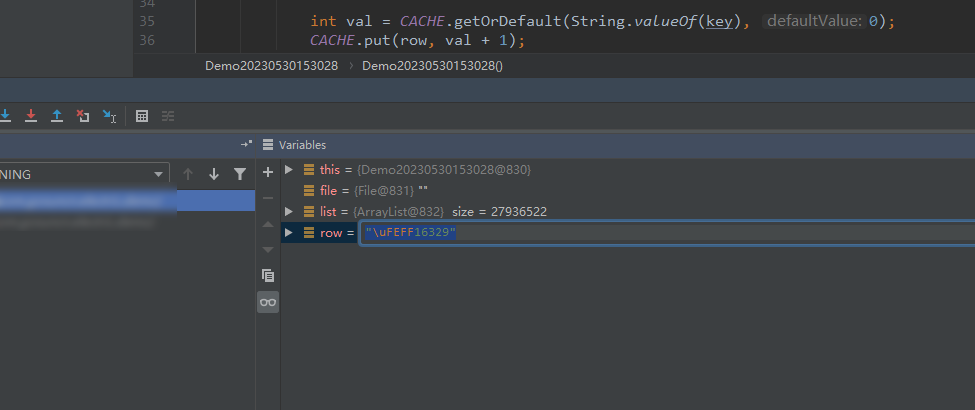
(4)此时,我们发现 row 变量的前面多出了一个 uFEFF 数据,这是什么呢?这是 UTF-8-BOM 编码添加的开头。如下:
(5)修改文本文件的编码为 UTF-8,如下图:
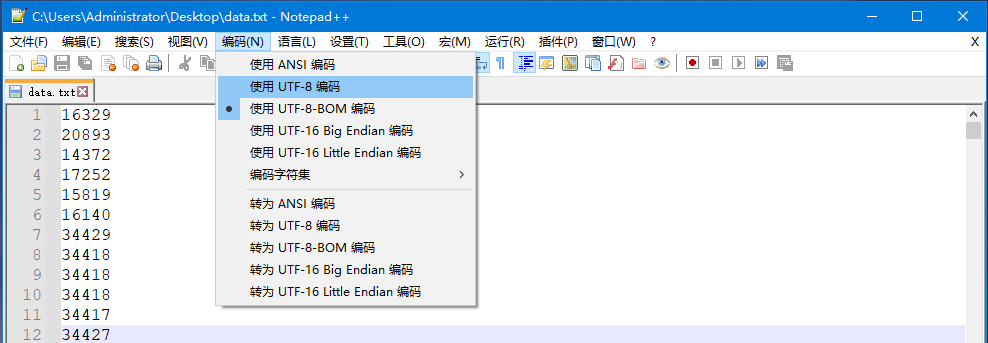
(6)再次运行程序,问题解决了。
UTF-8 与 UTF-8-BOM 区别
BOM 即 byte order mark,具体含义可百度百科或维基百科,UTF-8 文件中放置 BOM 主要是微软的习惯,但是放在别的系统上会出现问题。不含 BOM 的 UTF-8 才是标准形式,UTF-8 不需要 BOM 带 BOM 的 UTF-8 文件的开头会有 U+FEFF。
我们常常听人说,人们因工作过度而垮下来,但是实际上十有八九是因为饱受担忧或焦虑的折磨。 —— 卢伯克.J.






 川公网安备51010802032098
川公网安备51010802032098