本文将简单介绍 Spring Data JPA,以及怎样利用 Spring Boot JPA 访问数据库
Spring Data JPA 是 Spring Data 家族的一部分,利用它可以轻松实现基于 JPA 的数据存储。Spring Data JPA 模块是对基于 JPA 的数据访问层的增强,它使得利用 JPA 进行数据访问的 Spring 应用程序构建变得更加容易。
在相当长的一段时间内,实现应用程序的数据访问层一直很麻烦。必须编写大量的模版代码来执行简单 CRUD、分页和统计功能。Spring Data JPA 旨在通过减少模版代码,让用户仅仅关心实际业务代码,从而提高工作效率,显著改善数据访问层的实现。作为开发人员,您只需要编写 Repository 接口,包括自定义查找器方法,Spring Data 将自动提供实现。
Jpa、Hibernate、Spring Data Jpa 三者的关系
总的来说 JPA 是 ORM 规范,Hibernate、TopLink、OpenJPA 等是 JPA 规范的具体实现,这样做的好处是开发者仅仅面向 JPA 规范进行持久层的开发,而底层的实现则是可以切换的。Spring Data Jpa 则是在 JPA 之上添加另一层抽象(Repository层的实现),极大地简化持久层开发及 ORM 框架切换的成本。
下面将介绍怎样在 Spring Boot 中集成 Spring Data JPA,使用它来访问数据库。
springdata广告位
集成 Spring Data JPA
在进行下面配置之前,需要创建一个简单的 Spring Boot 项目。
添加 Maven 依赖
打开 pom.xml 文件,在该文件中添加如下依赖配置:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
配置数据源
修改 application.properties 属性配置文件,添加数据源,配置如下:
## database config
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/openjpa_learn?useSSL=false&serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=aaaaaa
创建数据表
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`salary` double DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
创建实体
import lombok.Data;
import javax.persistence.*;
@Data
@Entity
@Table
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column
private String name;
@Column
private Integer age;
@Column
private Float salary;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", salary=" + salary +
'}';
}
}
创建自定义 Repository
什么是 Repository?Repository 是一个空接口,即是一个标记接口,表示任何继承它的接口都是 Repository 接口类(Spring Data JPA 会自动扫描),可以利用 Repository 接口类访问数据库。
若我们继承了 Repository 接口,则该接口会被 Ioc 容器表示为一个 Repository Bean,放入到 IOC 容器中,进而可以在该接口中定义满足一定规范的方法。
实际上也可以通过 @RepositoryDefinition(domainClass = Person.class, idClass = Long.class) 来替代继承 Repository接口 。
Spring Data JPA 提供了多种 Repository 接口的子接口,如下:
CrudRepository:继承 Repository,实现一组 CURD 相关的方法
PagingAndSortingRespository:继承 CrudRepository,实现了一组分页排序相关的方法
JpaRepository:继承 PagingAndSortingRespository,实现了一组 JPA 规范相关的方法
自定义的XxxRepository:需要继承 JpaRepository,这样该接口就具备了通用的数据访问控制层的能力
JpaSpecificationExecutor:不属于 Repository 体系,实现一组 JPA Criteria 查询相关的方法
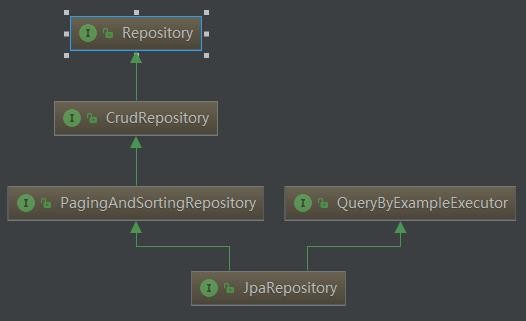
图:Spring Data JPA 的 Repository 继承关系图
本示例我们仅仅演示对 user 表的 CRUD 操作,因此自定义的 Repository 仅仅需要继承 CrudRepository 即可。代码如下:
import com.hxstrive.jpa.springboot_jpa.entity.User;
import org.springframework.data.repository.CrudRepository;
/**
* 用户DAO —— 数据访问对象
* @author Administrator
*/
public interface UserDao extends CrudRepository<User,Integer> {
}
客户端代码
下面将通过一个简单实例演示对 user 表的 CRUD 操作,代码如下:
import com.hxstrive.jpa.springboot_jpa.dao.UserDao;
import com.hxstrive.jpa.springboot_jpa.entity.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Optional;
@SpringBootTest
public class Demo1 {
// 这是我们自定义的用户访问对象
@Autowired
private UserDao userDao;
/**
* 插入数据
*/
@Test
public void insert() {
User user = new User();
user.setName("张三");
user.setAge(22);
userDao.save(user);
}
/**
* 更新数据
*/
@Test
public void update() {
Optional<User> optional = userDao.findById(1);
User user = optional.get();
if(null != user) {
user.setName("update-" + user.getName());
userDao.save(user);
}
}
/**
* 删除数据
*/
@Test
public void delete() {
Optional<User> optional = userDao.findById(1);
User user = optional.get();
if(null != user) {
userDao.delete(user);
}
}
/**
* 查询数据
*/
@Test
public void find() {
Iterable<User> iterable = userDao.findAll();
for (User user : iterable) {
System.out.println(user);
}
}
}






 川公网安备51010802032098
川公网安备51010802032098